| \(b_1\) | \(b_2\) | \(b_3\) | |
|---|---|---|---|
| \(a_1\) | .3 \(\times\) .2 = .06 | .3 \(\times\) .3 = .09 | .3 \(\times\) .5 = .15 |
| \(a_2\) | .7 \(\times\) .2 = .14 | .7 \(\times\) .3 = .21 | .7 \(\times\) .5 = .35 |
16.6 Selected tests
This section captures a selection of commonly used frequentist tests.
16.6.1 Pearson’s \(\chi^2\)-tests
![]()
There are many tests that use the \(\chi^2\)-distribution as an (approximate) sampling distribution. But given relevance and historical prominence, the name “\(\chi^2\)-test” is usually interpreted to refer to one of several flavor’s of what we could specifically call “Pearson’s \(\chi^2\)-test”.
We will look at two flavors here. Pearson’s \(\chi^2\)-test for goodness of fit tests whether an observed vector of counts is well explained by a given vector of predicted proportion. Pearson’s \(\chi^2\)-test for independence tests whether a (two-dimensional) table of counts could plausibly have been generated by a process of independently selecting the column and the row category. We will explain how both of these tests work based on an application of the BLJM data, which we load as usual:
data_BLJM_processed <- aida::data_BLJMThe focus is on the counts of music-subject choices:
BLJM_associated_counts <- data_BLJM_processed %>%
select(submission_id, condition, response) %>%
pivot_wider(names_from = condition, values_from = response) %>%
# drop the Beach-vs-Mountain condition
select(-BM) %>%
dplyr::count(JM,LB)
BLJM_associated_counts## # A tibble: 4 × 3
## JM LB n
## <chr> <chr> <int>
## 1 Jazz Biology 38
## 2 Jazz Logic 26
## 3 Metal Biology 20
## 4 Metal Logic 18Remember that the lecturer’s bold conjecture was that a preference for Logic over Biology goes together with a preference for Metal over Jazz. The visualization suggests that there might be such a trend, but the (statistical) jury is still out as to whether this conjecture has empirical support.
16.6.1.1 Pearson’s \(\chi^2\)-test for goodness of fit
“Goodness of fit” is a term used in model checking (a.k.a. model criticism, model validation, …). In such a context, tests for goodness-of-fit investigate whether a model’s predictions are compatible with the observed data. Pearson’s \(\chi^2\)-test for goodness of fit does exactly this for categorical data.
Categorical data is data where each data observation falls into one of several unordered categories. If we have \(k\) such categories, a prediction vector \(\vec{p} = \langle p_1, \dots, p_k \rangle\) is a probability vector of length \(k\) such that \(p_i\) gives the probability with which a single data observation falls into the \(i\)-th category. The likelihood of a single data observation is given by the Categorical distribution, and the likelihood of \(N\) data observations is given by the Multinomial distribution. These are generalizations of the Bernoulli and Binomial distributions, which expand the case of two unordered categories to more than two unordered categories.
The BLJM data supplies us with categorical data. Here is the vector of counts of how many participants selected a given music+subject pair:
# add category names
BLJM_associated_counts <- BLJM_associated_counts %>%
mutate(
category = str_c(
BLJM_associated_counts %>% pull(LB),
"-",
BLJM_associated_counts %>% pull(JM)
)
)
counts_BLJM_choice_pairs_vector <- BLJM_associated_counts %>% pull(n)
names(counts_BLJM_choice_pairs_vector) <- BLJM_associated_counts %>% pull(category)
counts_BLJM_choice_pairs_vector## Biology-Jazz Logic-Jazz Biology-Metal Logic-Metal
## 38 26 20 18Figure 16.10 shows a crude plot of these counts, together with a baseline prediction of equal proportion in each category.
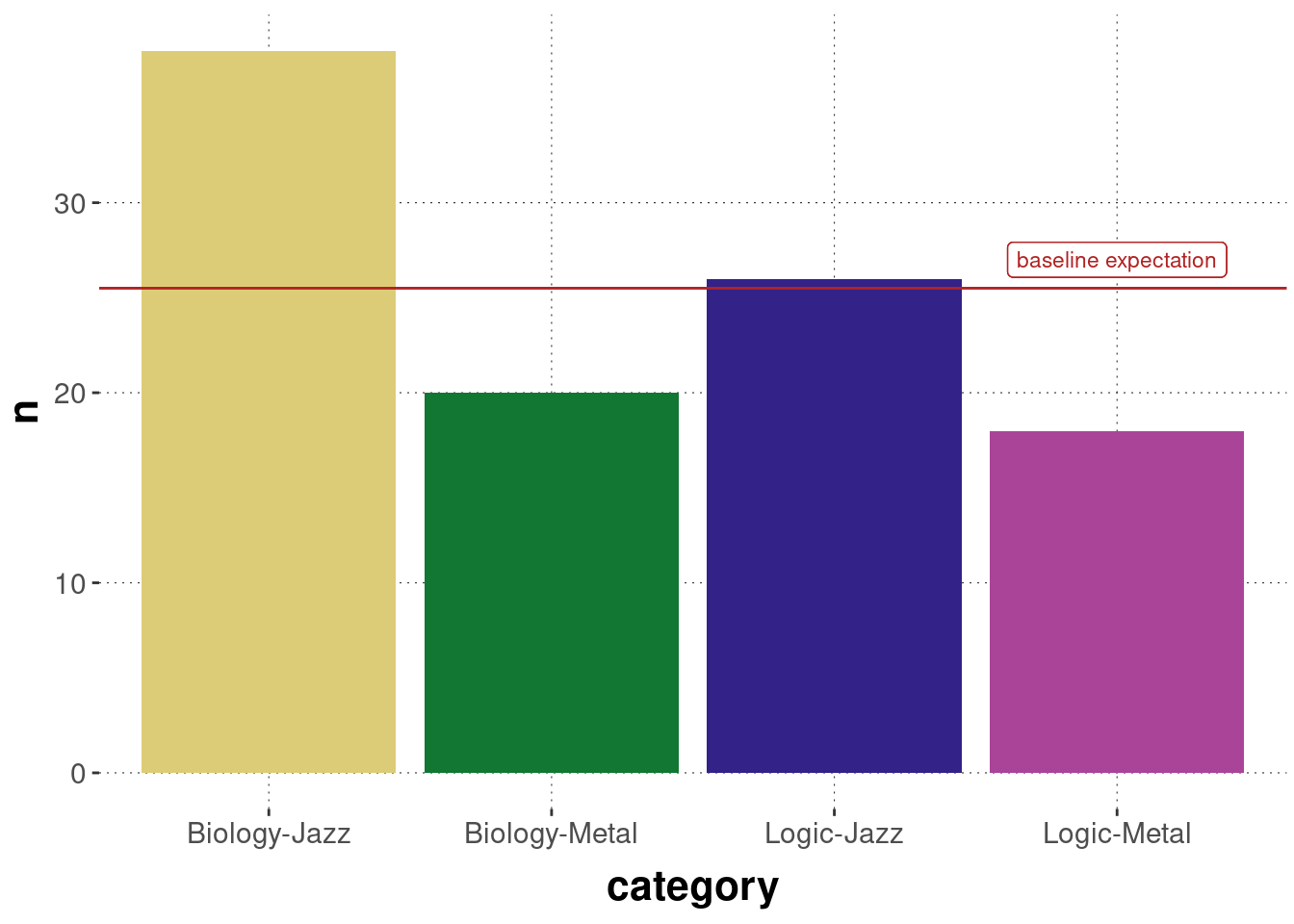
Figure 16.10: Observed counts of choice pairs of music+subject preference in the BLJM data.
Pearson’s \(\chi^2\)-test for goodness of fit allows us to test whether this data could plausibly have been generated by (a model whose predictions are given by) a prediction vector \(\vec{p} = \langle p_1, \dots, p_4 \rangle\), where \(p_1\) would be the predicted probability of a choice pair “Biology-Jazz” occurring for a single participant, and so on. Frequently, this test is used to check whether an equal baseline distribution could have generated the data. We do that here, too. We form the null hypothesis that \(\vec{p} = \vec{p}_0\) with \(p_{0i} = \frac{1}{4}\) for all categories \(i\).
Figure 16.11 shows a graphical representation of the model implicitly assumed in the background for a Pearson’s \(\chi^2\)-test for goodness of fit. The model assumes that the observed vector of counts (like our counts_BLJM_choice_pairs_vector from above) follows a Multinomial distribution.85 Each vector of (hypothetical) data is associated with a test statistic, called \(\chi^2\), which sums over the standardized squared deviation of the observed counts from the predicted baseline in each cell. It can be shown that, if the number of observations \(N\) is large enough, the sampling distribution of the \(\chi^2\) test statistic is approximated well enough by the \(\chi^2\)-distribution with \(k-1\) degrees of freedom (where \(k\) is the number of categories).86 Notice that the approximation by a \(\chi^2\)-distribution hinges on an approximation, which is only met when there are enough samples (just as we needed in the CLT). A rule-of-thumb is that at most 20% of all cells should have expected frequencies below 5 in order for the test to be applicable, i.e., \(np_i < 5\) for all \(i\) in Figure 16.11.
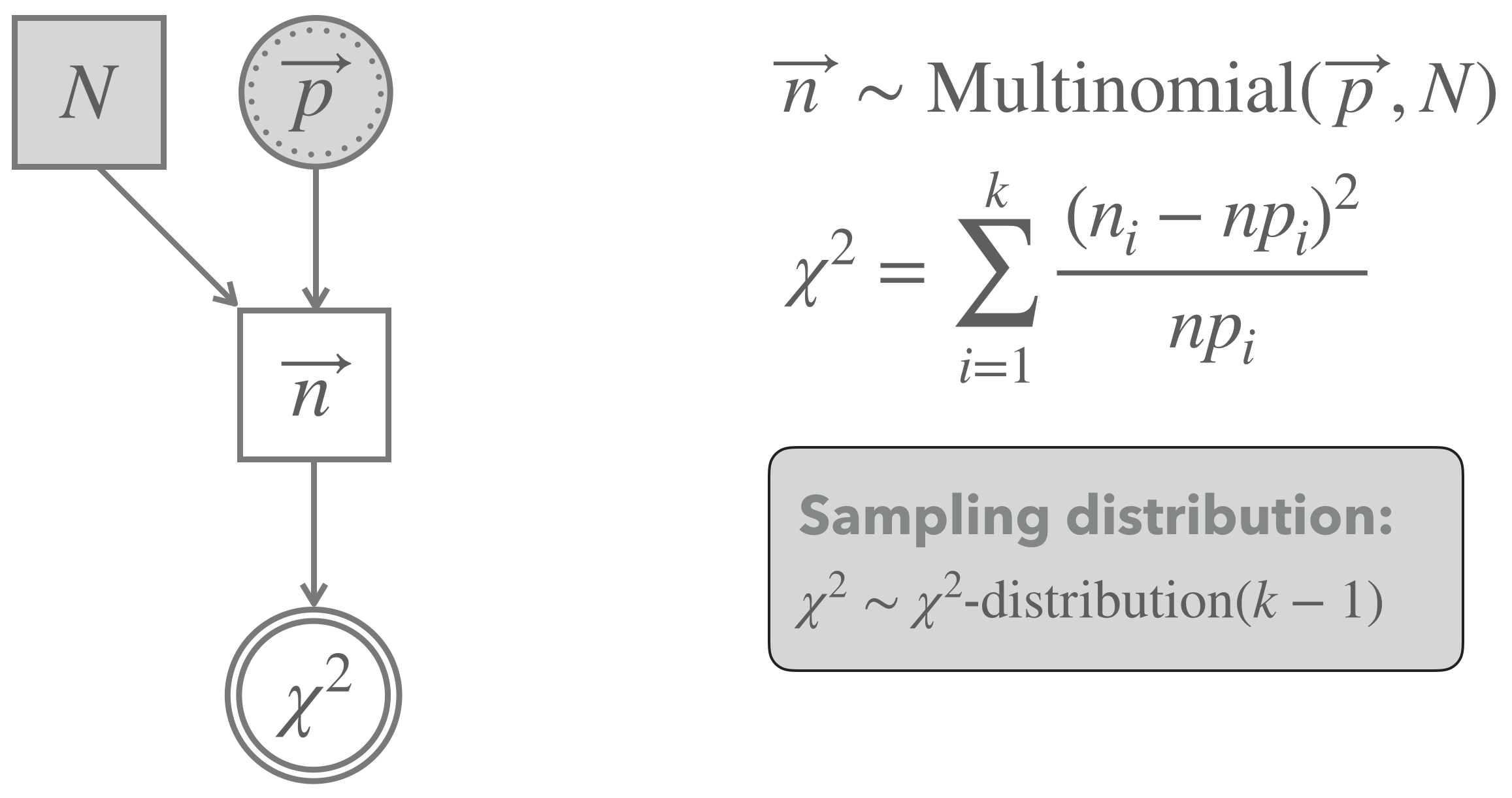
Figure 16.11: Graphical representation of Pearson’s \(\chi^2\)-test for goodness of fit (testing a vector of predicted proportion).
We can compute the \(\chi^2\)-value associated with the observed data \(t(D_{obs})\) as follows:
# observed counts
n <- counts_BLJM_choice_pairs_vector
# proportion predicted
p <- rep(1/4, 4)
# expected number in each cell
e <- sum(n) * p
# chi-squared for observed data
chi2_observed <- sum((n - e)^2 * 1/e)
chi2_observed## [1] 9.529412We can then compare this value to the sampling distribution, which is a \(\chi^2\)-distribution with \(k-1 = 3\) degrees of freedom. We compute the \(p\)-value associated with our data as the tail of the sampling distribution, as also shown in Figure 16.12:87
p_value_BLJM <- 1 - pchisq(chi2_observed, df = 3)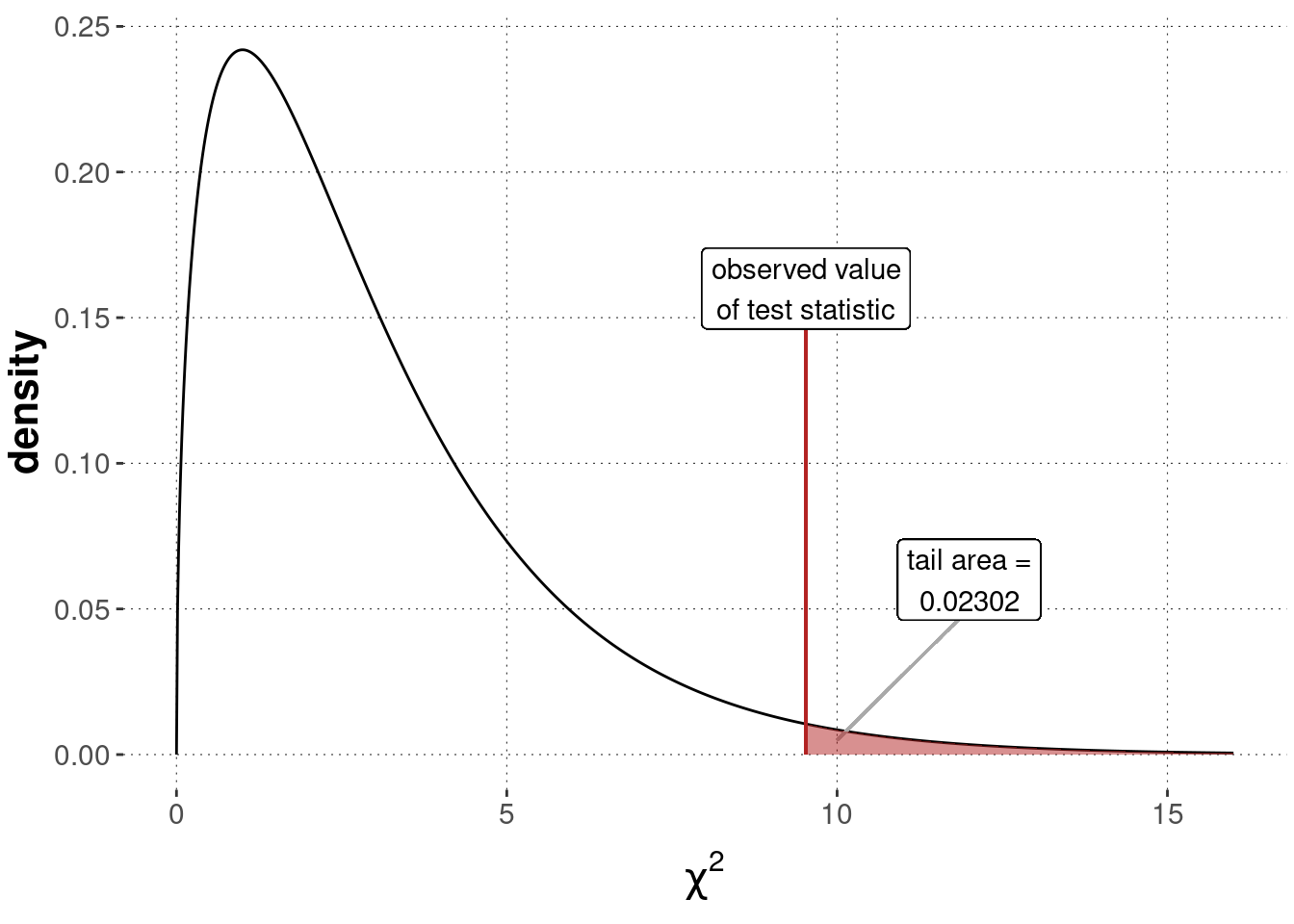
Figure 16.12: Sampling distribution for a Pearson’s \(\chi^2\)-test of goodness of fit (\(\chi^2\)-distribution with \(k-1 = 3\) degrees of freedom), testing a flat baseline null hypothesis based on the BLJM data.
Of course, these calculations can also be performed by using a built-in R function, namely chisq.test:
counts_BLJM_choice_pairs_vector <- BLJM_associated_counts %>% pull(n)
chisq.test(counts_BLJM_choice_pairs_vector)##
## Chi-squared test for given probabilities
##
## data: counts_BLJM_choice_pairs_vector
## X-squared = 9.5294, df = 3, p-value = 0.02302The common interpretation of our calculations would be to say that the test yielded a significant result, at least at the significance level of \(\alpha = 0.5\). In a research paper, we might report these results roughly as follows:
Observed counts deviated significantly from what is expected if each category (here: pair of music+subject choice) was equally likely (\(\chi^2\)-test, with \(\chi^2 \approx 9.53\), \(df = 3\) and \(p \approx 0.023\)).
Notice that this test is an “omnibus test of difference”. We can conclude from a significant test result that the whole vector of observations is unlikely to have been generated by chance. Still, we cannot conclude from this result (without doing anything else) why, where or how the observations deviated from the assumed prediction vector. Looking at the plot of the data in Figure 16.10 above, it seems intuitive to think that Metal is disproportionally disfavored and that the combination of Biology and Jazz looks particularly outliery when compared to the baseline expectation.
16.6.1.2 Pearson’s \(\chi^2\)-test of independence
The previous test of goodness of fit does not allow us to address the lecturer’s conjecture that a preference of Metal over Jazz goes with a preference of Logic over Biology. A slightly different kind of \(\chi^2\)-test is better suited for this. In Pearson’s \(\chi^2\)-test of independence, we look at a two-dimensional table of correlated data observations, like this one:
BLJM_table <- BLJM_associated_counts %>%
select(-category) %>%
pivot_wider(names_from = LB, values_from = n)
BLJM_table## # A tibble: 2 × 3
## JM Biology Logic
## <chr> <int> <int>
## 1 Jazz 38 26
## 2 Metal 20 18For easier computation and compatibility with the function chisq.test, we handle the same data but stored as a matrix:
counts_BLJM_choice_pairs_matrix <- matrix(
counts_BLJM_choice_pairs_vector,
nrow = 2,
byrow = T
)
rownames(counts_BLJM_choice_pairs_matrix) <- c("Jazz", "Metal")
colnames(counts_BLJM_choice_pairs_matrix) <- c("Biology", "Logic")
counts_BLJM_choice_pairs_matrix## Biology Logic
## Jazz 38 26
## Metal 20 18Pearson’s \(\chi^2\)-test of independence addresses the question of whether two-dimensional tabular count data like the above could plausibly have been generated by a prediction vector \(\vec{p}\), which results from the assumption that the realizations of row- and column-choices are stochastically independent. If row- and column-choices are independent, the probability of seeing an outcome result in cell \(ij\) is the probability of realizing row \(i\) times the probability of realizing column \(j\). So, under an independence assumption, we expect a matrix and a resulting vector of choice proportions like this:
# number of observations in total
N <- sum(counts_BLJM_choice_pairs_matrix)
# marginal proportions observed in the data
# the following is the vector r in the model graph
row_prob <- counts_BLJM_choice_pairs_matrix %>% rowSums() / N
# the following is the vector c in the model graph
col_prob <- counts_BLJM_choice_pairs_matrix %>% colSums() / N
# table of expected observations under independence assumption
# NB: %o% is the outer product of vectors
BLJM_expectation_matrix <- (row_prob %o% col_prob) * N
BLJM_expectation_matrix## Biology Logic
## Jazz 36.39216 27.60784
## Metal 21.60784 16.39216# the following is the vector p in the model graph
BLJM_expectation_vector <- as.vector(BLJM_expectation_matrix)
BLJM_expectation_vector## [1] 36.39216 21.60784 27.60784 16.39216Figure 16.13 shows a graphical representation of the \(\chi^2\)-test of independence. The main difference to the previous test of goodness of fit is that we do no longer just fix any-old prediction vector \(\vec{p}\), but consider \(\vec{p}\) the deterministic results of independence and the best estimates (based on the data at hand) of the row- and column probabilities.
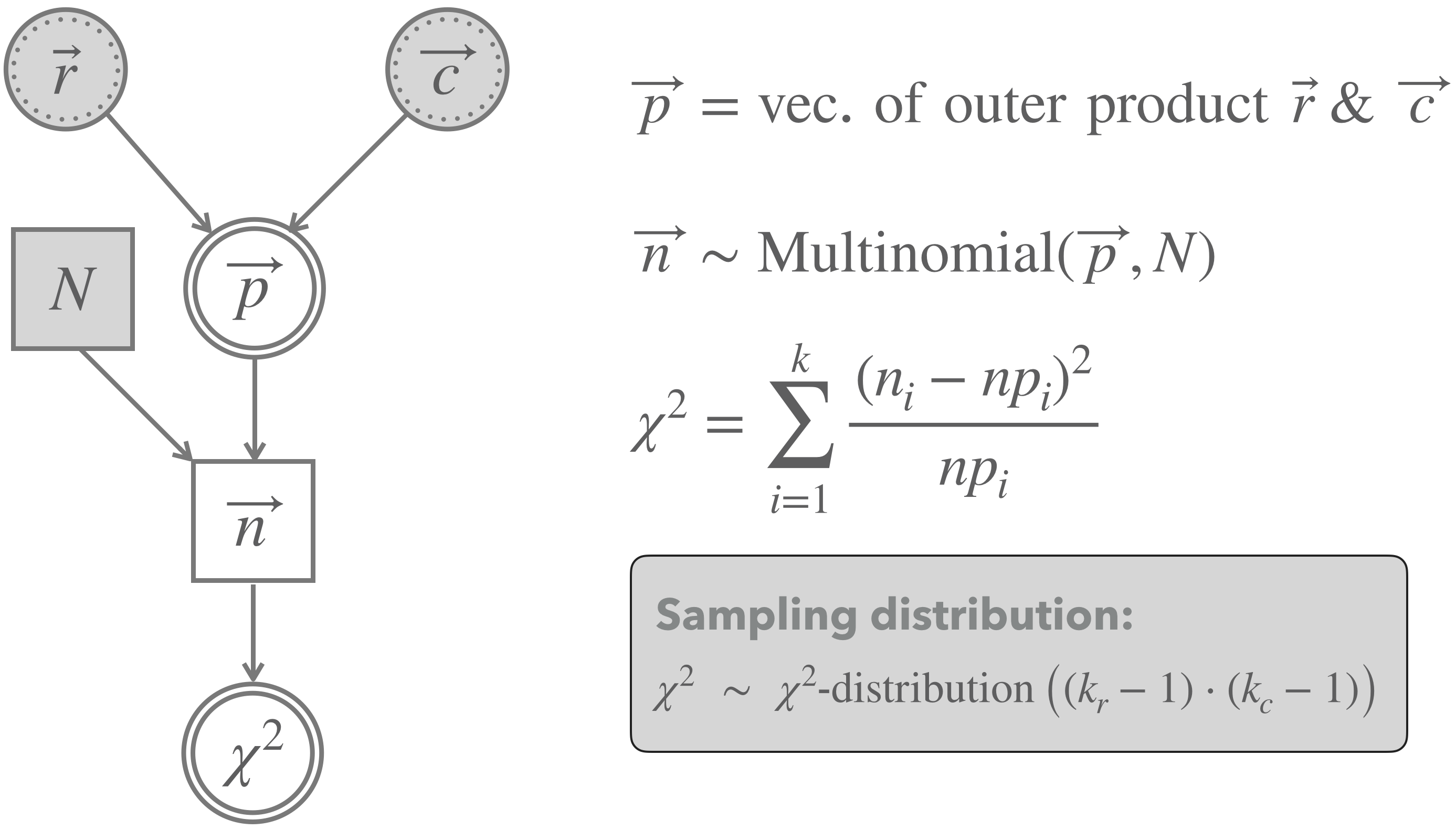
Figure 16.13: Graphical representation of Pearson’s \(\chi^2\)-test for independence.
We can compute the observed \(\chi^2\)-test statistic and the \(p\)-value as follows:
chi2_observed <- sum(
(counts_BLJM_choice_pairs_matrix - BLJM_expectation_matrix)^2 /
BLJM_expectation_matrix
)
p_value_BLJM <- 1 - pchisq(q = chi2_observed, df = 1)
round(p_value_BLJM, 5)## [1] 0.50615Figure 16.14 shows the sampling distribution, the value of the test statistic for the observed data and the \(p\)-value.
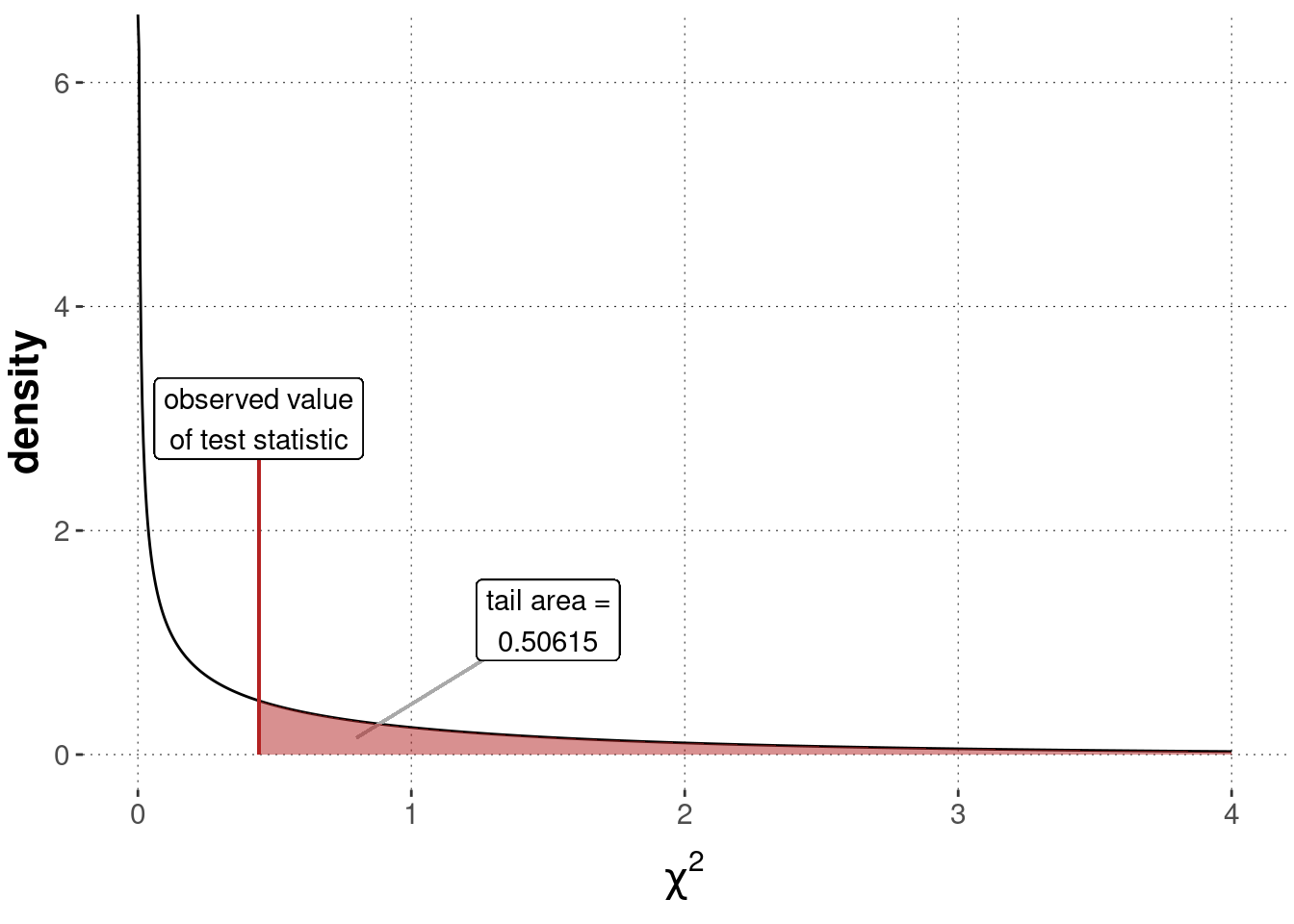
Figure 16.14: Sampling distribution for a Pearson’s \(\chi^2\) test of independence (\(\chi^2\)-distribution with \(1\) degree of freedom), testing a flat baseline null hypothesis based on the BLJM data.
We can also use the built-in function chisq.test in R to obtain this result more efficiently:
chisq.test(
# supply data as a matrix, not as a vector, for a test of independence
counts_BLJM_choice_pairs_matrix,
# do not use the default correction (because we didn't introduce it)
correct = FALSE
)##
## Pearson's Chi-squared test
##
## data: counts_BLJM_choice_pairs_matrix
## X-squared = 0.44202, df = 1, p-value = 0.5061With a \(p\)-value of about 0.5061, we should conclude that there is no indication of strong evidence against the assumption of independence. Consequently, there is no evidence in favor of the lecturer’s conjecture of dependence of musical and academic preferences. In a research paper, we might report this result as follows:
A \(\chi^2\)-test of independence did not yield a significant test result (\(\chi^2\)-test, with \(\chi^2 \approx 0.44\), \(df = 1\) and \(p \approx 0.5\)). Therefore, we cannot claim to have found any evidence for the research hypothesis of dependence.
Exercise 16.5: \(\chi^2\)-test of independence
Let us assume that there are two unordered categorical variables \(A\) and \(B\). Categorical variable \(A\) has two levels \(a_1\) and \(a_2\). Categorical variable \(B\) has three levels \(b_1\), \(b_2\) and \(b_3\). Let us further assume that the (marginal) probabilities of a choice from categories \(A\) or \(B\) is as follows:
\[ P(A=a_i)=\begin{cases} 0.3 &\textbf{if \(i=1\)} \\ 0.7 &\textbf{if \(i=2\)} \end{cases} \quad P(B=b_i)=\begin{cases} 0.2 &\textbf{if \(i=1\)}\\ 0.3 &\textbf{if \(i=2\)}\\ 0.5 &\textbf{if \(i=3\)} \end{cases} \]
- If observations of pairs of instances from categories \(A\) and \(B\) are stochastically independent, what would the expected joint probability of each pair of potential observations be?
- Imagine you observe the following table of counts for each pair of instances of categories \(A\) and \(B\):
| \(b_1\) | \(b_2\) | \(b_3\) | |
|---|---|---|---|
| \(a_1\) | 1 | 26 | 3 |
| \(a_2\) | 19 | 4 | 47 |
Which of the \(p\)-values given below would you expect to see when feeding this table into a Pearson \(\chi^2\)-test of independence? (only one correct answer)
- \(p \approx 1\)
- \(p \approx 0.5\)
- \(p \approx 0\)
- I expect no result because the test is not suitable for this kind of data.
The correct answer is \(p \approx 0\).
- Explain the answer you gave in the previous part in at most three concise sentences.
As the marginal proportions of observed counts for the table in b. equal the marginal probabilities given above, the joint probability table in a. actually gives the predicted probabilities under the assumption of independence. Comparing prediction against observed proportion (obtained by dividing the table in b. by the total count of 100), we see severe divergences, especially in the middle column.
16.6.2 z-test
The Central Limit Theorem tells us that, given enough data, we can treat means of repeated samples from any arbitrary probability distribution as approximately normally distributed. Notice in addition that if \(X\) and \(Y\) are random variables following a normal distribution, then so is \(Z = X - Y\) (see also the chapter on the normal distribution). It now becomes clear how research questions about means and differences between means (e.g., in the Mental Chronometry experiment) can be addressed, at least approximately: We conduct tests that hinge on a sampling distribution which is a normal distribution (usually a standard normal distribution).
The \(z\)-test is perhaps the simplest of a family of tests that rely on normality of the sampling distribution. Unfortunately, what makes it so simple is also what makes it inapplicable in a wide range of cases. The \(z\)-test assumes that a quantity that is normally distributed has an unknown mean (to be inferred by testing), but it also assumes that the variance is known. Since we do not know the variance in most cases of practical relevance, the \(z\)-test needs to be replaced by a more adequate test, usually a test from the \(t\)-test family, to be discussed below.
We start with the \(z\)-test nonetheless because of the added benefit to our understanding. Figure 16.15 shows the model that implicitly underlies a \(z\)-test. It checks whether the data \(\vec{x}\), which are assumed to be normally distributed with known \(\sigma\), could have been generated by a hypothesized mean \(\mu = \mu_0\). The sampling distribution of the derived test statistic \(z\) is a standard normal distribution.
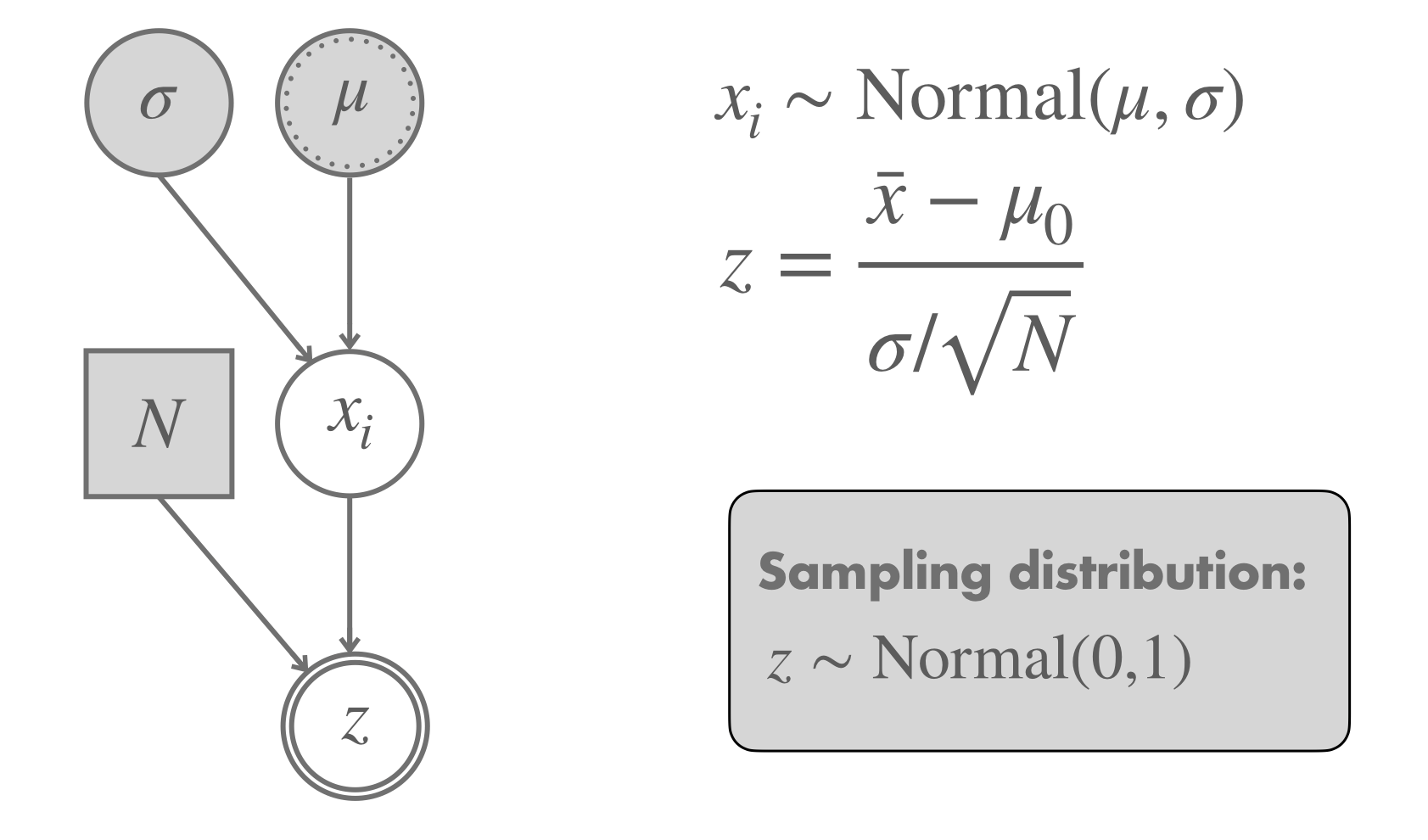
Figure 16.15: Graphical representation of a \(z\)-test.
We know that IQ test results are normally distributed around a mean of 100 with a standard deviation of 15. This holds when the sample is representative of the whole population. But suppose we have reason to believe that the sample is from CogSci students. The standard deviation in a sample from CogSci students might still plausibly be fixed to 15, but we’d like to test the assumption that this sample was generated by a mean \(\mu = 100\), our null hypothesis.
For illustration, suppose we observed the following data set of IQ test results:
# fictitious IQ data
IQ_data <- c(87, 91, 93, 97, 100, 101, 103, 104,
104, 105, 105, 106, 108, 110, 111,
112, 114, 115, 119, 121)
mean(IQ_data)## [1] 105.3The mean of this data set is 105.3. Suspicious!
Following the model in Figure 16.15, we calculate the value of the test statistic for the observed data.
# number of observations
N <- length(IQ_data)
# null hypothesis to test
mu_0 <- 100
# standard deviation (known/assumed as true)
sd <- 15
z_observed <- (mean(IQ_data) - mu_0) / (sd / sqrt(N))
z_observed %>% round(4)## [1] 1.5802We focus on a one-sided \(p\)-value because our “research” hypothesis is that CogSci students have, on average, a higher IQ. Since we observed a mean of 105.3 in the data, which is higher than the critical value of 100, we test the null hypothesis \(\mu = 100\) against an alternative hypothesis that assumes that the data was generated by a mean bigger than 100 (which is exactly our research hypothesis).
As before, we can then compute the \(p\)-value by checking the area under the sampling distribution, here a standard normal, in the appropriate way. Figure 16.16 shows this result graphically.
p_value_IQ_data_ztest <- 1 - pnorm(z_observed)
p_value_IQ_data_ztest %>% round(6)## [1] 0.057036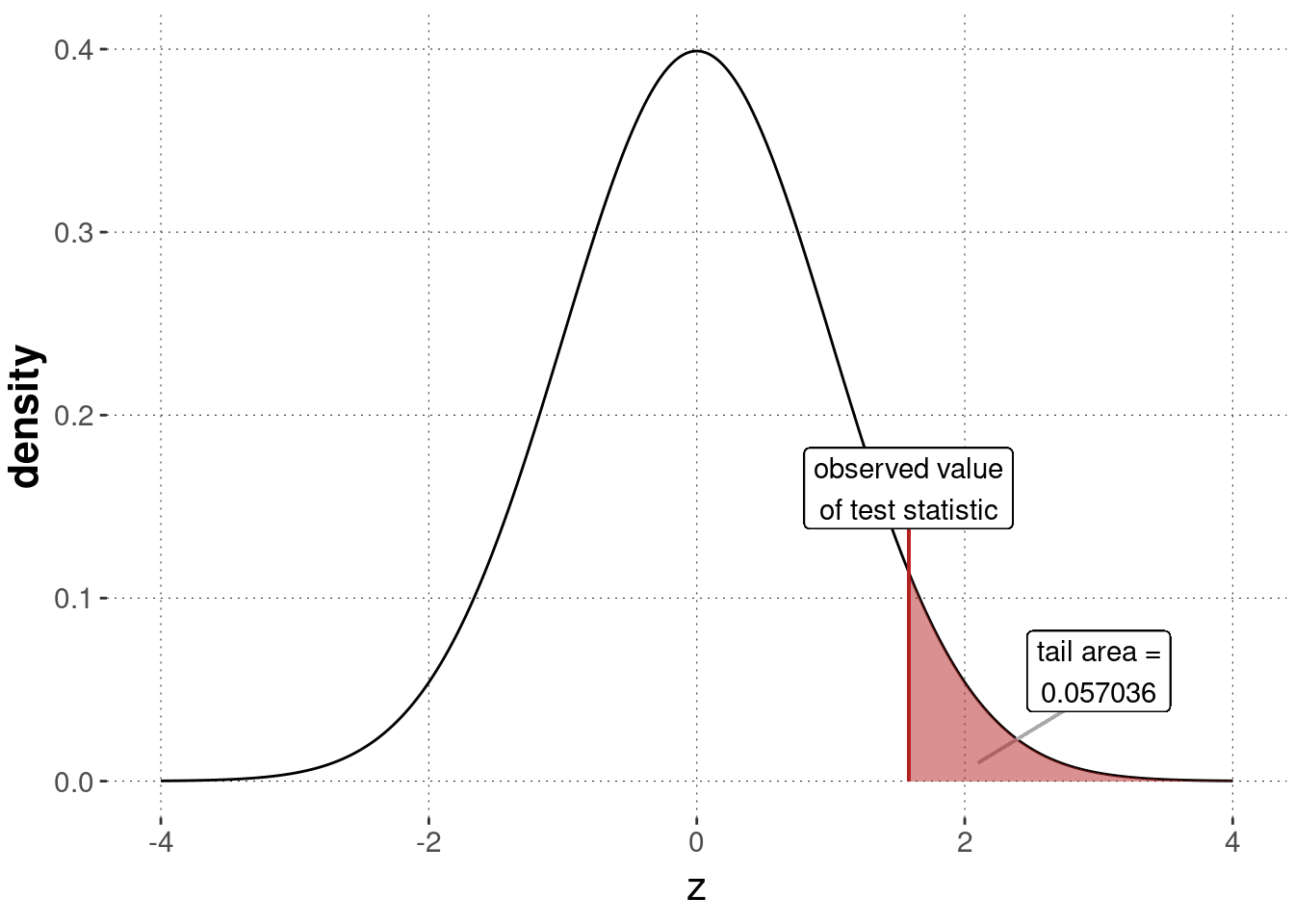
Figure 16.16: Sampling distribution for a \(z\)-test, testing the null hypothesis based on the assumption that the IQ-data was generated by \(\mu = 100\) (with assumed/known \(\sigma\)).
We can also use a ready-made function for the \(z\)-test. However, as the \(z\)-test is so uncommon, it is not built into core R. We need to rely on the BSDA package to find the function z.test.
BSDA::z.test(x = IQ_data, mu = 100, sigma.x = 15, alternative = "greater")##
## One-sample z-Test
##
## data: IQ_data
## z = 1.5802, p-value = 0.05704
## alternative hypothesis: true mean is greater than 100
## 95 percent confidence interval:
## 99.78299 NA
## sample estimates:
## mean of x
## 105.3The conclusion to be drawn from this test could be formulated in a research report as follows:
We tested the null hypothesis of a mean equal to 100, assuming a known standard deviation of 15, in a one-sided \(z\)-test against the alternative hypothesis that the data was generated by a mean greater than 100 (our research hypothesis). The test was not significant (\(N = 20\), \(z \approx 1.5802\), \(p \approx 0.05704\)), giving us no indication of strong evidence against the assumption that the mean is at most 100.
16.6.3 t-tests
In most practical applications where a \(z\)-test might be useful, the standard deviation is not known. If unknown, it should also not lightly be fixed by clever guess-work. This is where the family of \(t\)-tests comes in. We will look at two examples of these: the one-sample \(t\)-test, which compares one set of samples to a fixed mean, and the two-sample \(t\)-test, which compares the means of two sets of samples.
16.6.3.1 One-sample \(t\)-test
The simplest example of this family, namely a \(t\)-test for one metric vector \(\vec{x}\) of normally distributed observations, tests the null hypothesis that \(\vec{x}\) was generated by some \(\mu = \mu_0\) (just like the \(z\)-test). However, unlike the \(z\)-test, a one-sample \(t\)-test does not assume that the standard deviation is known. It rather uses the observed data to obtain an estimate for this parameter. More concretely, a one-sample \(t\)-test for \(\vec{x}\) estimates the standard deviation in the usual way (see Chapter 5):
\[\hat{\sigma}_x = \sqrt{\frac{1}{n-1} \sum_{i=1}^n (x_i - \mu_{\vec{x}})^2}\]
Figure 16.17 shows a graphical representation of a one-sample \(t\)-test model. The light shading of the node for the standard deviation indicates that this parameter is estimated from the observed data. Importantly, the distribution of the test statistic \(t\) is no longer well approximated by a normal distribution when the sample size is low. It is better captured by a Student’s \(t\) distribution.
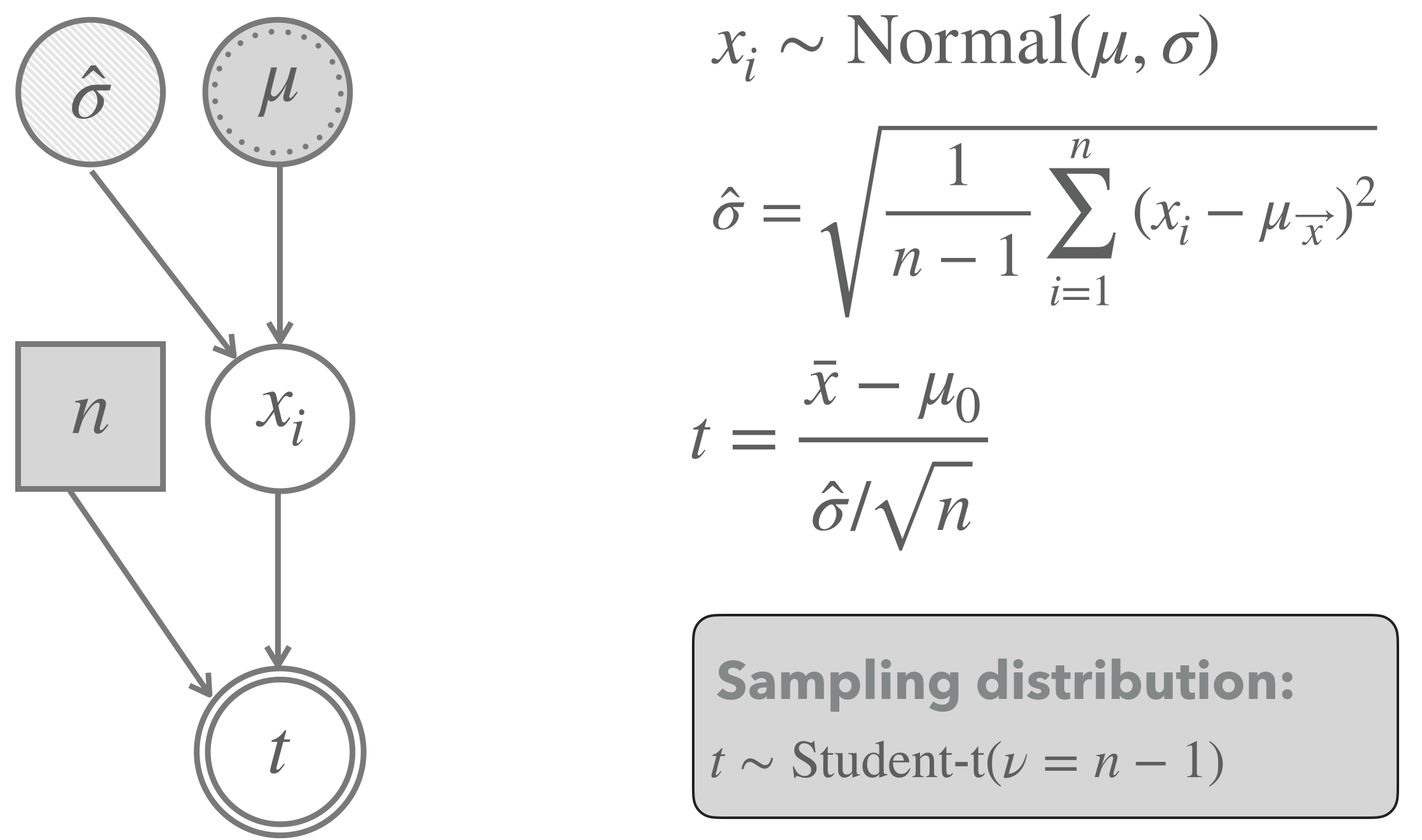
Figure 16.17: Graphical representation of the model underlying a frequentist one-sample \(t\)-test. Notice that the lightly shaded node for the standard deviation represents that the value for this parameter is estimated from the data.
Let’s revisit our IQ-data set from above to calculate a \(t\)-test. Using a \(t\)-test implies that we are now assuming that the standard deviation is actually unknown. We can calculate the value of the test statistic for the observed data and use this to compute a \(p\)-value, much like in the case of the \(z\)-test before.
N <- length(IQ_data)
# fix the null hypothesis
mean_0 <- 100
# unlike in a z-test, we use the sample to estimate the SD
sigma_hat <- sd(IQ_data)
t_observed <- (mean(IQ_data) - mean_0) / sigma_hat * sqrt(N)
t_observed %>% round(4)## [1] 2.6446We calculate the relevant one-sided \(p\)-value using the cumulative distribution function pt of the \(t\)-distribution.
p_value_t_test_IQ <- 1 - pt(t_observed, df = N - 1)
p_value_t_test_IQ %>% round(6)## [1] 0.007992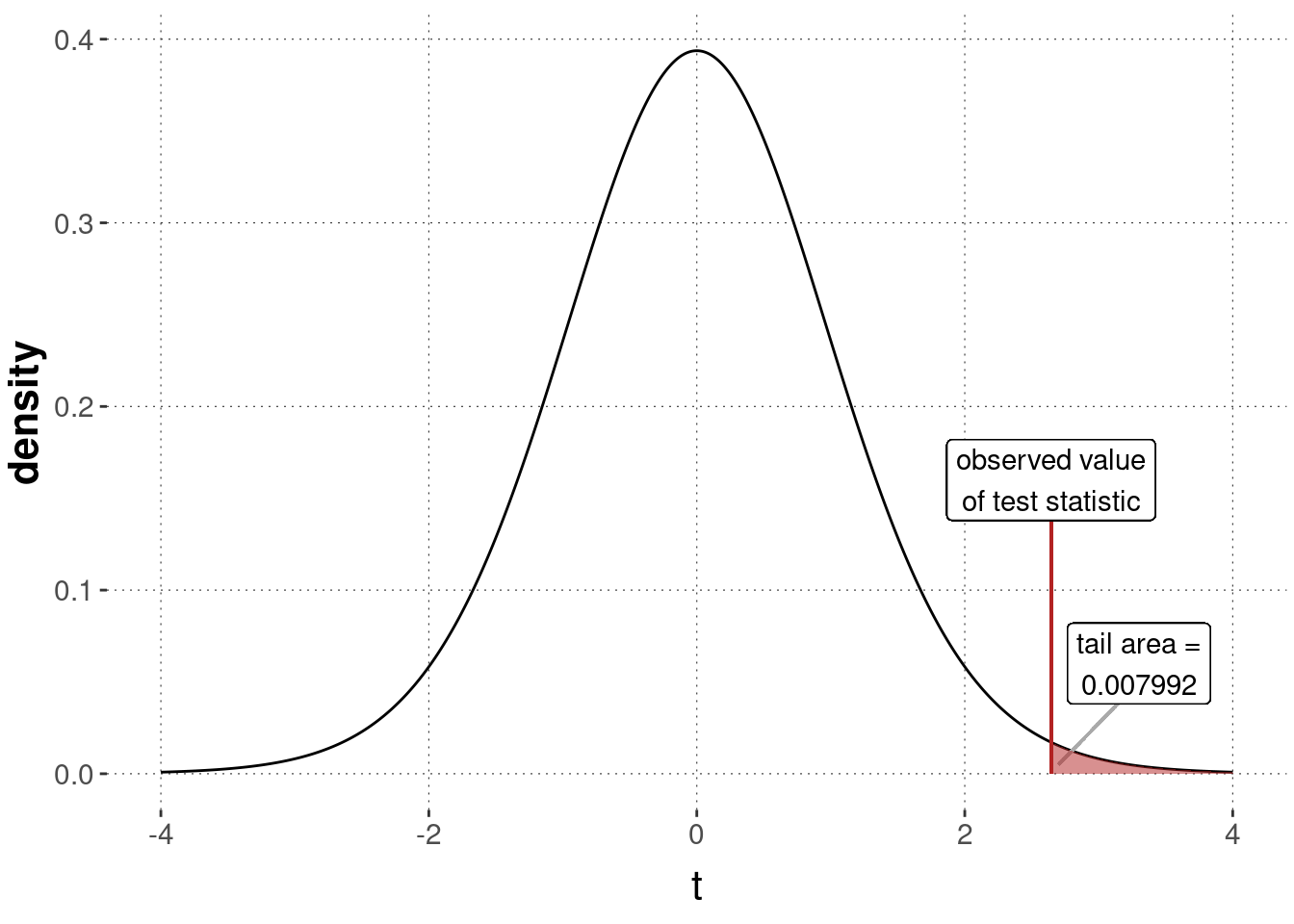
Figure 16.18: Sampling distribution for a \(t\)-test, testing the null hypothesis that the IQ-data was generated by \(\mu = 100\) (with unknown \(\sigma\)).
Compare these calculations against the built-in function t.test:
t.test(x = IQ_data, mu = 100, alternative = "greater")##
## One Sample t-test
##
## data: IQ_data
## t = 2.6446, df = 19, p-value = 0.007992
## alternative hypothesis: true mean is greater than 100
## 95 percent confidence interval:
## 101.8347 Inf
## sample estimates:
## mean of x
## 105.3These results could be stated in a research report much like so:
We tested the null hypothesis of a mean equal to 100, assuming an unknown standard deviation, using a one-sided, one-sample \(t\)-test against the alternative hypothesis that the data was generated by a mean greater than 100 (our research hypothesis). The significant test result (\(N = 20\), \(t \approx 2.6446\), \(p \approx 0.007992\)) suggests that the data provides strong evidence against the assumption that the mean is not bigger than 100.
Notice that the conclusions we draw from the previous \(z\)-test and this one-sample \(t\)-test are quite different. Why is this so? Well, it is because we (cheekily) chose a data set IQ_data that was actually not generated by a normal distribution with a standard deviation of 15, contrary to what we said about IQ-scores normally having this standard deviation. The assumption about \(\sigma\) fed into the \(z\)-test was (deliberately!) wrong. The result of the \(t\)-test, at least for this example, is better. The data in IQ_data are actually samples from \(\text{Normal}(105,10)\). This demonstrates why the one-sample \(t\)-test is usually preferred over a \(z\)-test: unshakable, true knowledge of \(\sigma\) is very rare.
16.6.3.2 Two-sample \(t\)-test (for unpaired data with equal variance and unequal sample sizes)
![]()
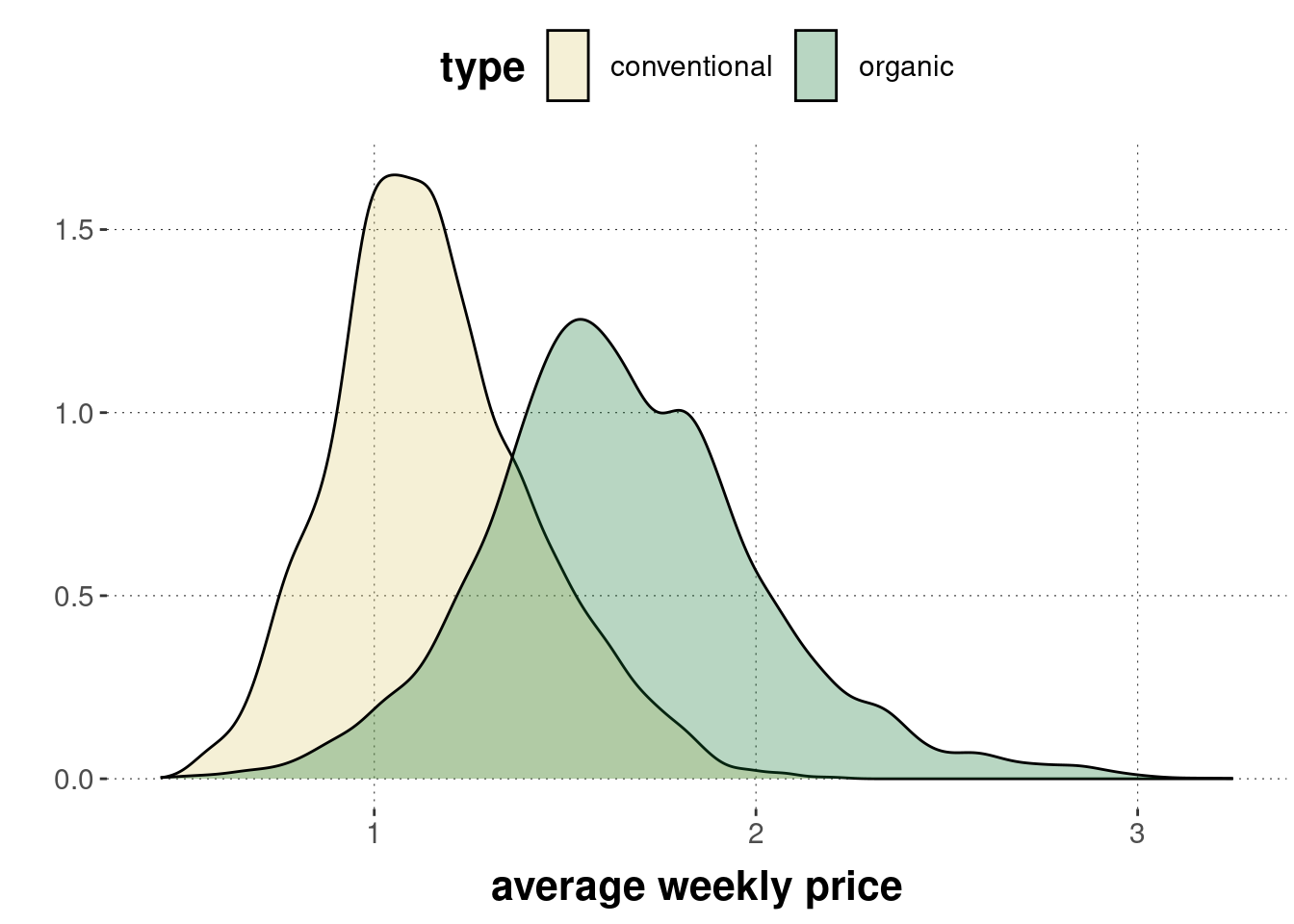
The “mother of all experimental designs” compares two groups of measurements. We give a drug to one group of patients, a placebo to another. We take a metric measure (say, blood sugar level) and ask whether there is a difference between these two groups. Section 9 introduced the \(T\)-Test Model for a Bayesian approach. Here, we look at a corresponding model for a frequentist approach, a so-called two-sample \(t\)-test. There are different kinds of such two-sample \(t\)-tests. The differences lie, e.g., in whether we assume that both groups have equal variance, in whether the sample sizes are the same in both groups, or in whether observations are paired (e.g., as in a within-subjects design, where we get two measurements from each participant, one from each condition/group). Here, we focus on unpaired data (as from a between-subjects design), assume equal variance but (possibly) unequal sample sizes. The case we look at is the avocado data, where we want to specifically investigate whether the weekly average price of organically grown avocados is higher than that of conventionally grown avocados.88
We here consider the preprocessed avocado data set (see Appendix Chapter D.5 for details on how this preprocessing was performed).
avocado_data <- aida::data_avocadoRemember that the distribution of prices looks as follows:
A graphical representation of the two-sample \(t\)-test (for unpaired data with equal variance and unequal sample sizes), which we will apply to this case, is shown in Figure 16.19. The model assumes that we have two vectors of metric measurements \(\vec{x}_A\) and \(\vec{x}_B\), with length \(n_A\) and \(n_B\), respectively. These are the price measures for conventionally grown and for organically grown avocados. The model assumes that measures in both \(\vec{x}_A\) and \(\vec{x}_B\) are i.i.d. samples from a normal distribution. The mean of one group (group \(B\) in the graph) is assumed to be some unknown \(\mu\). Interestingly, this parameter will cancel out eventually: the approximation of the sampling distribution turns out to be independent of this parameter.89 The mean of the other group (group \(A\) in the graph) is computed as \(\mu + \delta\), so with some additive parameter \(\delta\) indicating the difference between means of these groups. This \(\delta\) is the main parameter of interest for inferences regarding hypotheses concerning differences between groups. Finally, the model assumes that both groups have the same standard deviation, an estimate of which is derived from the data (in a rather convoluted looking formula that is not important for our introductory concerns). As indicated in Figure 16.19, the sampling distribution for this model is an instance of Student’s \(t\)-distribution with mean 0, standard deviation 1 and degrees of freedom \(\nu\) given as \(n_A + n_B - 2\).

Figure 16.19: Graphical representation of the model underlying a frequentist two-population \(t\)-test (for unpaired data with equal variance and unequal sample sizes). Notice that the light shading of the node for the standard deviation indicates that the value for this parameter is estimated from the data.
Figure 16.19 gives us the template to compute the value of the test statistic for the observed data:
# fix the null hypothesis: no difference between groups
delta_0 <- 0
# data (group A)
x_A <- avocado_data %>%
filter(type == "organic") %>% pull(average_price)
# data (group B)
x_B <- avocado_data %>%
filter(type == "conventional") %>% pull(average_price)
# sample mean for organic (group A)
mu_A <- mean(x_A)
# sample mean for conventional (group B)
mu_B <- mean(x_B)
# numbers of observations
n_A <- length(x_A)
n_B <- length(x_B)
# variance estimate
sigma_AB <- sqrt(
( ((n_A - 1) * sd(x_A)^2 + (n_B - 1) * sd(x_B)^2 ) /
(n_A + n_B - 2) ) * (1/n_A + 1/n_B)
)
t_observed <- (mu_A - mu_B - delta_0) / sigma_AB
t_observed ## [1] 105.5878We can use the value of the test statistic for the observed data to compute a one-sided \(p\)-value, as before. Notice that we use a one-sided test because we hypothesize that organically grown avocados are more expensive, not just that they have a different price (more expensive or cheaper).
p_value_t_test_avocado <- 1 - pt(q = t_observed, df = n_A + n_B - 2)
p_value_t_test_avocado## [1] 0Owing to number imprecision, the calculated \(p\)-value comes up as a flat zero. We have a lot of data, and the task of defending that conventionally grown avocados are not less expensive than organically grown is very tough. This also shows in the corresponding picture in Figure 16.20.
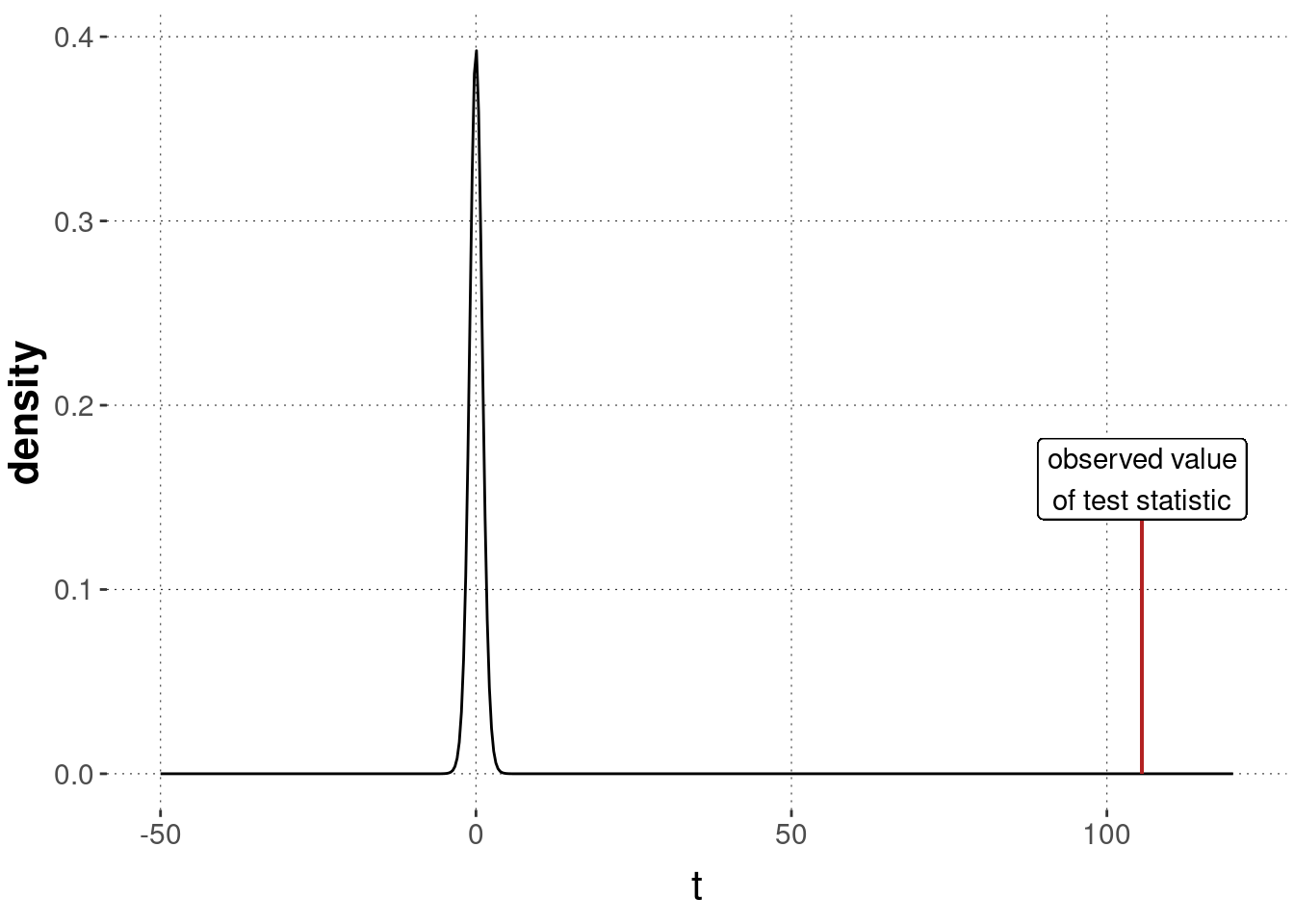
Figure 16.20: Sampling distribution for a two-sample \(t\)-test, testing the null hypothesis of no difference between groups, based on the avocado data.
We can also, of course, calculate this test result with the built-in function t.test:
t.test(
x = x_A, # first vector of data measurements
y = x_B, # second vector of data measurements
paired = FALSE, # measurements are to be treated as unpaired
var.equal = TRUE, # we assume equal variance in both groups
mu = 0 # NH is delta = 0 (name 'mu' is misleading!)
)##
## Two Sample t-test
##
## data: x_A and x_B
## t = 105.59, df = 18247, p-value < 2.2e-16
## alternative hypothesis: true difference in means is not equal to 0
## 95 percent confidence interval:
## 0.4867522 0.5051658
## sample estimates:
## mean of x mean of y
## 1.653999 1.158040The result could be reported as follows:
We conducted a two-sample \(t\)-test of differences of means (unpaired samples, equal variance, unequal sample sizes) to compare the average weekly price of conventionally grown avocados to that of organically grown avocados. The test result indicates a significant difference for the null hypothesis that conventionally grown avocados are not cheaper (\(N_A = 9123\), \(N_B = 9126\), \(t \approx 105.59\), \(p \approx 0\)).
Exercise 16.6: Two-sample \(t\)-test
Your fellow student is skeptical of her flatmate’s claim that pizzas from place \(A\) have a smaller diameter than place \(B\) (both pizzerias have just one pizza size, namely \(\varnothing\ 32\ cm\)). She decides to test that claim with a two-sample \(t\)-test and sets \(H_0: \mu_A = \mu_B\) (\(\delta = 0\)), \(H_a: \mu_A < \mu_B\), \(\alpha = 0.05\). She then asks your class to always measure the pizza’s diameter if ordered from one of the two places. At the end of the semester, she has the following table:
| Pizzeria \(A\) | Pizzeria \(B\) | |
|---|---|---|
| mean | 30.9 | 31.8 |
| standard deviation | 2.3 | 2 |
| sample size | 38 | 44 |
- How many degrees of freedom \(\nu\) are there?
\(\nu = n_A+n_B-2 = 38+44-2 = 80\) degrees of freedom.
- Given the table above, calculate the test statistic \(t\).
\[ \hat{\sigma}=\sqrt{\frac{(n_A-1)\hat{\sigma}_A^2+(n_B-1)\hat{\sigma}^2_B}{n_A+n_B-2}(\frac{1}{n_A}+\frac{1}{n_B})}\\ \hat{\sigma}=\sqrt{\frac{37\cdot2.3^2+43\cdot2^2}{80}(\frac{1}{38}+\frac{1}{44})}\approx 0.47\\ t=((\bar{x}_A-\bar{x}_B)-\delta)\cdot\frac{1}{\hat{\sigma}}\\ t=\frac{30.9-31.8}{0.47}\approx -1.91 \]
- Look at this so-called t table and determine the critical value to be exceeded in order to get a statistically significant result. NB: We are looking for the critical value that is on the left side of the distribution. So, in order to have a statistically significant result, the test statistic from b. has to be smaller than the negated critical value in the table.
The critical value is -1.664.
- Compare the test statistic from b. with the critical value from c. and interpret the result.
The calculated test statistic from b. is smaller than the critical value. We therefore know that the \(p\)-value is statistically significant. The fellow student should reject the null hypothesis of equal pizza diameters.
16.6.4 ANOVA
ANOVA is short for “analysis of variance”. It’s an umbrella term for a number of different models centered around testing the influence of one or several categorical predictors on a metric measurement. In previous sections, we have summoned regression models for this task. This is indeed the more modern and preferred approach, especially when the regression modeling also takes random effects (so-called hierarchical modeling) into account. Nonetheless, it is good to have a basic understanding of ANOVAs, as they are featured prominently in a lot of published research papers, whose findings are still relevant. Also, in some areas of empirical science, ANOVAs are still commonly used.
Here we are just going to cover the most basic type of ANOVA, which is called a one-way ANOVA.
A one-way ANOVA is, in regression jargon, a suitable approach for the case of a single categorical predictor with more than two levels (otherwise a \(t\)-test would be enough) and a metric dependent variable.
For illustration we will here consider a fictitious case of metric measurement for three groups: A, B, and C.
These groups are levels of a categorical predictor group.
We want to address the research question of whether the means of the measurements of groups A, B and C could plausibly be identical.
The main idea behind analysis of variance is not to look at the means of measurements to be compared, but rather to compare the between-group variances to the within-group variances. Whence the name “analysis of variance”. While mathematically complex, the idea is quite intuitive. Figure 16.21 shows four different (made-up) data sets, each with different measurements for groups A, B and C. It also shows the “pooled data”, i.e., the data from all three groups combined. What is also shown in each panel is the so-called F-statistic, which is a number derived from a sample in the following way.
We have \(k \ge 2\) groups of metric observations. For group \(1 \le j \le k\), there are \(n_j\) observations. Let \(x_{ij}\) be the observation \(1 \le i \le n_j\) for group \(1 \le j \le k\). Let \(\bar{x}_j = \frac{1}{n_j} \sum_{i = 1}^{n_j} x_{ij}\) be the mean of group \(j\) and let \(\bar{\bar{x}} = \frac{1}{k} \sum_{j=1}^k \frac{1}{n_j} \sum_{i=1}^{n_j} x_{ij}\) be the grand mean of all data points. The between-group variance measures how much, on average, the mean of each group deviates from the grand mean of all data points (where distance is squared distance, as usual):
\[ \hat{\sigma}_{\mathrm{between}} = \frac{\sum_{j=1}^k n_j (\bar{x}_j - \bar{\bar{x}})^2}{k-1} \] The within-group variance is a measure of the average variance of the data points inside of each group:
\[ \hat{\sigma}_{\mathrm{within}} = \frac{\sum_{j=1}^k \sum_{i=1}^{n_j} (x_{ij} - \bar{x}_j)^2}{\sum_{i=1}^k (n_i - 1)} \]
Now, if the means of different groups are rather different from each other, the between-group variance should be high. But absolute numbers may be misleading, so we need to scale the between-group variance also by how much variance we see, on average, in each group, i.e., the within-group variance. That is why the \(F\)-statistic is defined as:
\[ F = \frac{\hat{\sigma}_{\mathrm{between}}}{\mathrm{\hat{\sigma}_{\mathrm{within}}}} \] For illustration, Figure 16.21 shows four different scenarios with associated measures of \(F\).
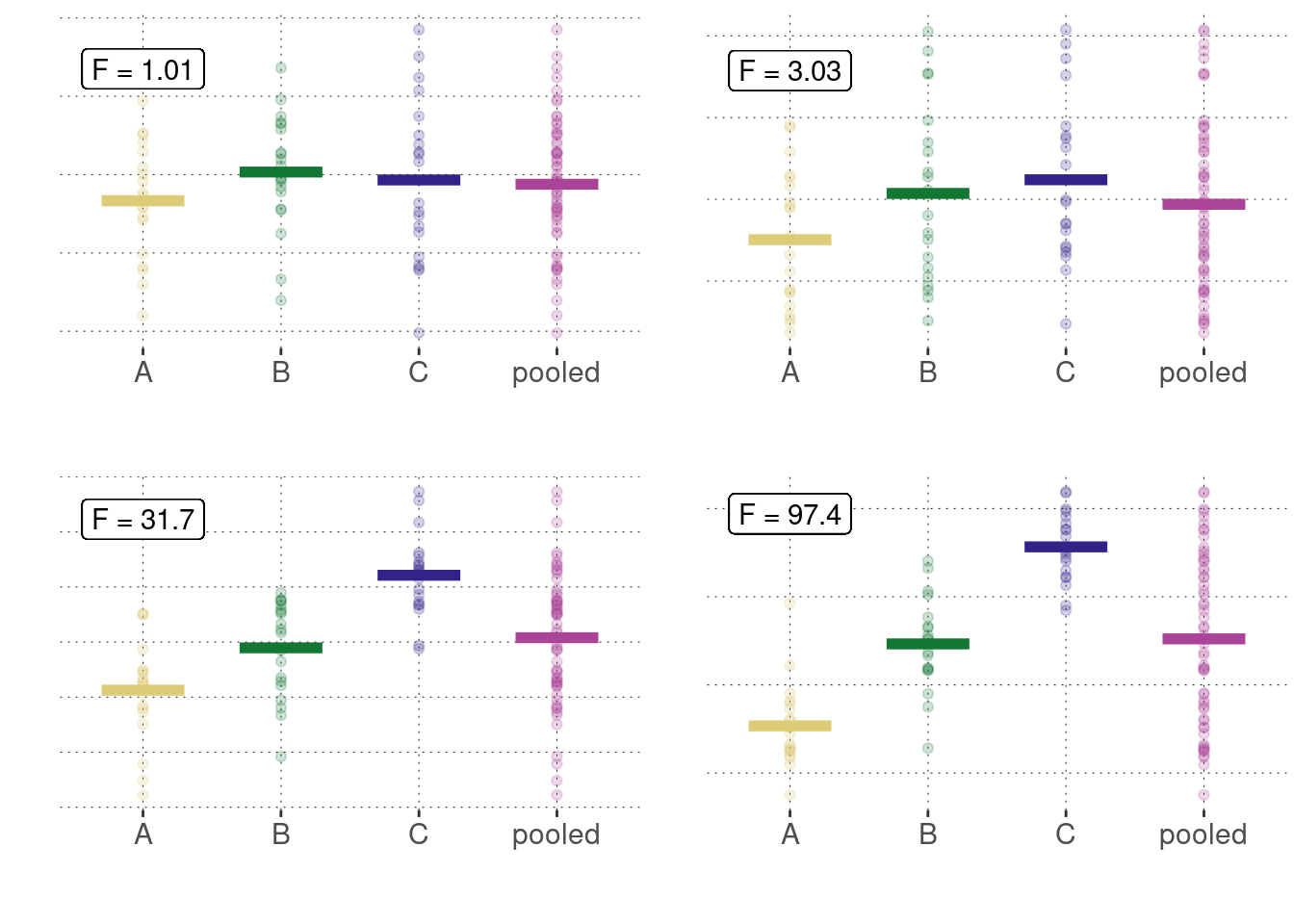
Figure 16.21: Different examples of metric measurements for three groups (A, B, C), shown here together with a plot of the combined (= pooled) data. We see that, as the means of measurements go apart, so does the ratio of between-group variance and within-group variance.
It can be shown that, under the assumption that the \(k\) groups have identical means, the sampling distribution of the \(F\) statistic follows an \(F\)-distribution with appropriate parameters (which is, unsurprisingly, the distribution constructed for exactly this purpose):
\[ F \sim F\mathrm{\text{-}distribution}\left(k - 1, \sum_{i=1}^k (n_i - 1) \right) \]
The complete frequentist model of a one-way ANOVA is shown in Figure 16.22. Notice that the null hypothesis of equal means is not shown explicitly, but rather only a single mean \(\mu\) is shown, which functions as the mean for all groups.
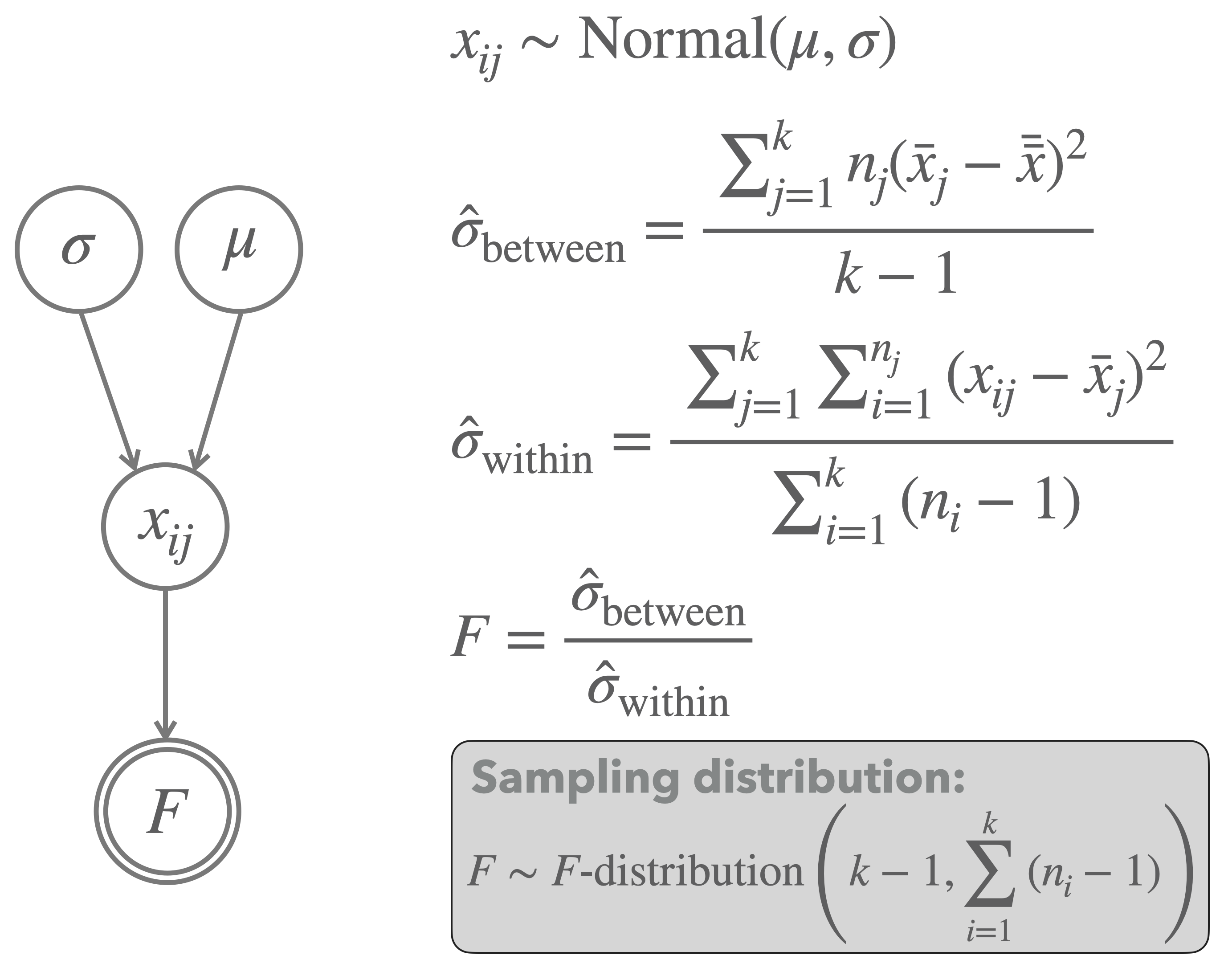
Figure 16.22: Graphical representation of the model underlying a one-way ANOVA.
Let’s consider some concrete, but fictitious data for a full example:
# fictitious data
x_A <- c(78, 43, 60, 60, 60, 50, 57, 58, 64, 64, 56, 62, 66, 53, 59)
x_B <- c(52, 53, 51, 49, 64, 60, 45, 50, 55, 65, 76, 62, 62, 45)
x_C <- c(78, 66, 74, 57, 75, 64, 64, 53, 63, 60, 79, 68, 68, 47, 63, 67)
# number of observations in each group
n_A <- length(x_A)
n_B <- length(x_B)
n_C <- length(x_C)
# in tibble form
anova_data <- tibble(
condition = c(
rep("A", n_A),
rep("B", n_B),
rep("C", n_C)
),
value = c(x_A, x_B, x_C)
)Here’s a plot of this data:
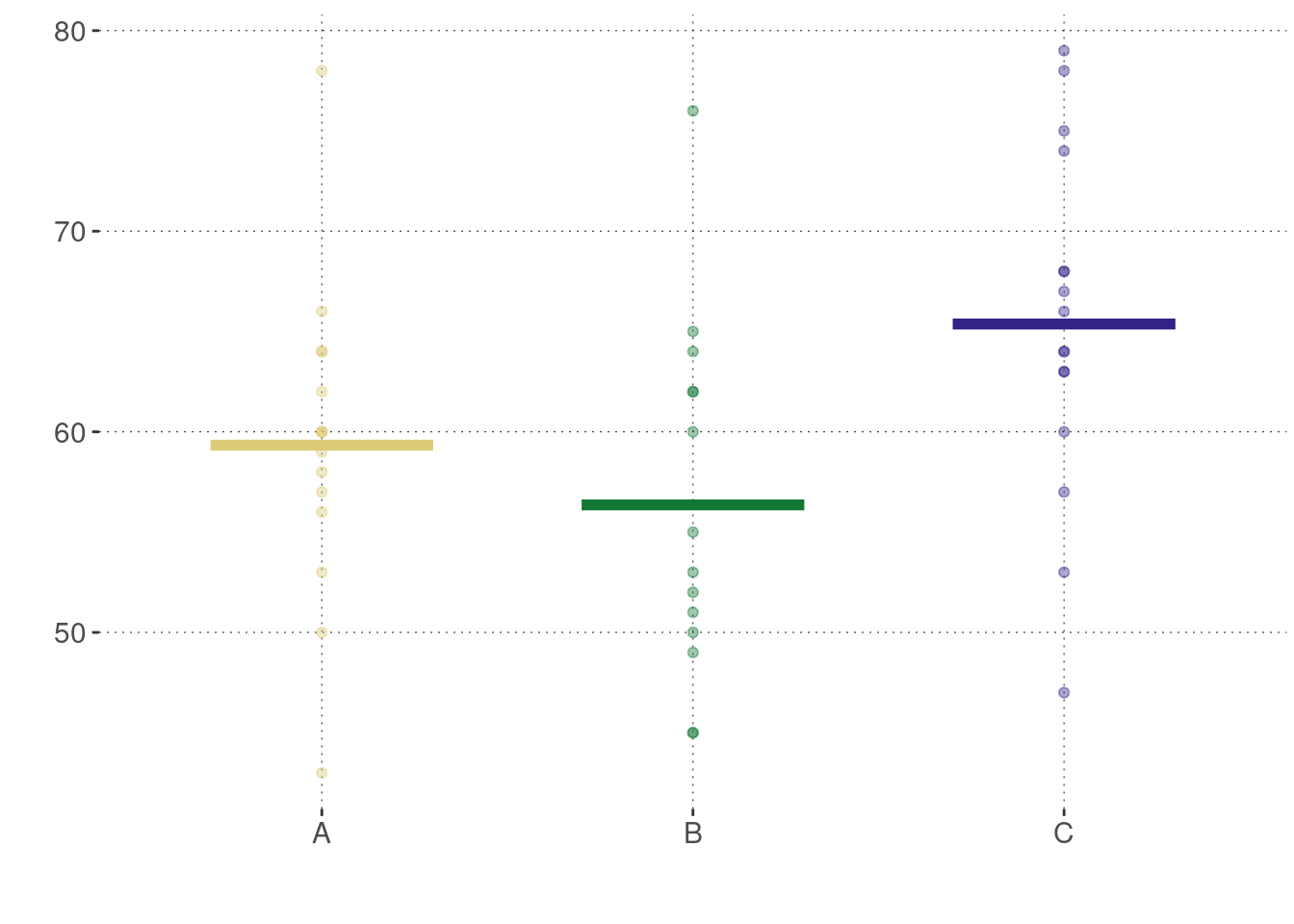
We want to know whether it is plausible to entertain the idea that the means of these three groups are identical. We can calculate the one-way ANOVA explicitly as follows, following the calculations described in Figure 16.22:
# compute grand_mean
grand_mean <- anova_data %>% pull(value) %>% mean()
# compute degrees of freedom (parameters to F-distribution)
df1 <- 2
df2 <- n_A + n_B + n_C - 3
# between-group variance
between_group_variance <- 1/df1 *
(
n_A * (mean(x_A) - grand_mean)^2 +
n_B * (mean(x_B) - grand_mean)^2 +
n_C * (mean(x_C) - grand_mean)^2
)
# within-group variance
within_group_variance <- 1/df2 *
(
sum((x_A - mean(x_A))^2) +
sum((x_B - mean(x_B))^2) +
sum((x_C - mean(x_C))^2)
)
# test statistic of observed data
F_observed <- between_group_variance / within_group_variance
# retrieving the p-value (using the F-distribution)
p_value_anova <- 1 - pf(F_observed, 2, n_A + n_B + n_C - 3)
p_value_anova %>% round(4)## [1] 0.0172Compare this to the result of calling R’s built-in function aov:
aov(formula = value ~ condition, anova_data) %>% summary()## Df Sum Sq Mean Sq F value Pr(>F)
## condition 2 640.8 320.4 4.485 0.0172 *
## Residuals 42 3000.3 71.4
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1To report these results, we could use a statement like this:
Based on a one-way ANOVA, we find evidence against the assumption of equal means across all groups (\(F(2, 42) \approx 4.485\), \(p \approx 0.0172\)).
16.6.5 Linear regression
Significance testing for linear regression parameters follows the same logic as for other models as well.
In particular, it can be shown that the relevant test statistic for ML-estimates of regression coefficients \(\hat\beta_i\), under the assumption that the true model has \(\beta_i = 0\), follows a \(t\)-distribution.
We can run a linear regression model (with a Gaussian noise function) using the built-in function glm (for “generalized linear model”):
fit_murder_mle <- glm(
formula = murder_rate ~ low_income,
data = aida::data_murder
)If we inspect a summary for the model fit, we see the results of a \(t\)-test, one for each coefficient, based on the null-hypothesis that this coefficient’s true value is 0.
summary(fit_murder_mle)##
## Call:
## glm(formula = murder_rate ~ low_income, data = aida::data_murder)
##
## Deviance Residuals:
## Min 1Q Median 3Q Max
## -9.1663 -2.5613 -0.9552 2.8887 12.3475
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -29.901 7.789 -3.839 0.0012 **
## low_income 2.559 0.390 6.562 3.64e-06 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## (Dispersion parameter for gaussian family taken to be 30.38125)
##
## Null deviance: 1855.20 on 19 degrees of freedom
## Residual deviance: 546.86 on 18 degrees of freedom
## AIC: 128.93
##
## Number of Fisher Scoring iterations: 2So, in the case of the murder_data, we would conclude that there is strong evidence against the assumption that the data could have been generated by a model whose slope parameter for low_income is set to 0.
16.6.6 Likelihood-Ratio Test
The likelihood-ratio (LR) test is a very popular frequentist method of model comparison. The LR-test assimilates model comparison to frequentist hypothesis testing. It defines a suitable test statistic and supplies an approximation of the sampling distribution. The LR-test first and foremost applies to the comparison of nested models, but there are results about how approximate results can be obtained when comparing non-nested models with an LR-test (Vuong 1989).
A frequentist model \(M_i\) is nested inside another frequentist model \(M_j\) iff \(M_i\) can be obtained from \(M_j\) by fixing at least one of \(M_j\)’s free parameters to a specific value. If \(M_i\) is nested under \(M_j\), \(M_i\) is called the nested model, and \(M_j\) is called the nesting model or the encompassing model. Obviously, the nested model is simpler (of lower complexity) than the nesting model.
For example, we had the two-parameter exponential model of forgetting previously in Chapter 10:
\[ \begin{aligned} P(D = \langle k, N \rangle \mid \langle a, b\rangle) & = \text{Binom}(k,N, a \exp (-bt)), \ \ \ \ \text{where } a,b>0 \end{aligned} \]
We wanted to explain the following “forgetting data”:
# time after memorization (in seconds)
t <- c(1, 3, 6, 9, 12, 18)
# proportion (out of 100) of correct recall
y <- c(.94, .77, .40, .26, .24, .16)
# number of observed correct recalls (out of 100)
obs <- y * 100An example of a model that is nested under this two-parameter model is the following one-parameter model, which fixes \(a = 1.1\).
\[ \begin{aligned} P(D = \langle k, N \rangle \mid b) & = \text{Binom}(k,N, 1.1 \ \exp (-bt)), \ \ \ \ \text{where } b>0 \end{aligned} \]
Here’s an ML-estimation for the nested nested model (the best fit for the nesting model bestExpo was obtained in Chapter 10):
nLL_expo_nested <- function(b) {
# calculate predicted recall rates for given parameters
theta <- 1.1 * exp(-b * t) # one-param exponential model
# avoid edge cases of infinite log-likelihood
theta[theta <= 0.0] <- 1.0e-4
theta[theta >= 1.0] <- 1 - 1.0e-4
# return negative log-likelihood of data
- sum(dbinom(x = obs, prob = theta, size = 100, log = T))
}
bestExpo_nested <- optim(
nLL_expo_nested,
par = 0.5,
method = "Brent",
lower = 0,
upper = 20
)
bestExpo_nested## $par
## [1] 0.1372445
##
## $value
## [1] 19.21569
##
## $counts
## function gradient
## NA NA
##
## $convergence
## [1] 0
##
## $message
## NULLThe LR-test looks at the likelihood ratio of the nested model \(M_0\) over the encompassing model \(M_1\) using the following test statistic:
\[\text{LR}(M_1, M_0) = -2\log \left(\frac{P_{M_0}(D_\text{obs} \mid \hat{\theta}_0)}{P_{M_1}(D_\text{obs} \mid \hat{\theta}_1)}\right)\]
We can calculate the value of this test statistic for the current example as follows:
LR_observed <- 2 * bestExpo_nested$value - 2 * bestExpo$value
LR_observed## [1] 1.098429If the simpler (nested) model is true, the sampling distribution of this test statistic approximates a \(\chi^2\)-distribution with \(d\) if we have more and more data. The degrees of freedom \(d\) are given by the difference in free parameters, i.e., the number of parameters the nested model fixes to specific values, but which are free in the nesting model.
We can therefore calculate the \(p\)-value for the LR-test for our current example like so:
p_value_LR_test <- 1 - pchisq(LR_observed, 1)
p_value_LR_test## [1] 0.2946111The \(p\)-value of this test quantifies the evidence against the assumption that the data was generated by the simpler model. A significant test result would therefore indicate that it would be surprising if the data was generated by the simpler model. This is usually taken as evidence in favor of the more complex, nesting model. Given the current \(p\)-value \(p \approx 0.2946\), we would conclude that there is no strong evidence against the simpler model. Often this may lead researchers to favor the nested model due to its simplicity; the data at hand does not seem to warrant the added complexity of the nesting model; the nested model seems to suffice.
Exercise 16.7
TRUE OR FALSE?
- The nested model usually has more free parameters than the nesting model.
- When we perform the LR-test, we initially assume that the nested model is more plausible.
- An LR-test can only compare the nested model with nesting models.
- If the LR-test result has a \(p\)-value equal to 1.0, one can conclude that it’s a piece of evidence in favor of the simpler model.
- False
- True
- False
- True
References
Vuong, Quang H. 1989. “Likelihood Ratio Tests for Model Selection and Non-Nested Hypotheses.” Econometrica 57 (2): 307–33.
Notice that for economy of presentation, we now (again) gloss over the “raw” data of individual choices and present the summarized count data instead. In the previous case of the Binomial Test, it made good pedagogical sense to tease apart the “raw” observations from the summarized counts because this helped to show what the test statistic is for a case, where the choice of it was very, very obvious; so much so, that we would normally not even bother to make it explicit. Now that we understood what a test statistic is in principle, we can gloss over some steps of data summarizing.↩︎
A proof of this fact is non-trivial, but an intuition why this might be so is available if we think of each cell independently first. In each cell, with more and more samples, the distribution of counts will approximate a normal distribution by the CLT. The \(\chi^2\)-distribution rests (by construction) on a sum of squared samples from a standard normal distribution.↩︎
Notice that this is a one-sided test due to the nature of the test statistic, which measures squared deviation from the baseline and not deviation in any particular direction (because it is hard to say what a “direction” would be in this case anyway).↩︎
Notice that the original avocado data set contains information also about the place of measurement, which would in principle allow us to treat the price measurements as paired samples (one pair for each week and place). For simplicity, but with a note of care that this makes us lose possibly relevant structural information, we here treat the avocado data as if it contained unpaired samples.↩︎
This is intuitively so because the test statistic is concerned only with the difference between sample means.↩︎