D.8 Politeness data
D.8.1 Nature, origin and rationale of the data
![]()
The politeness data is borrowed from Winter and Grawunder (2012).98
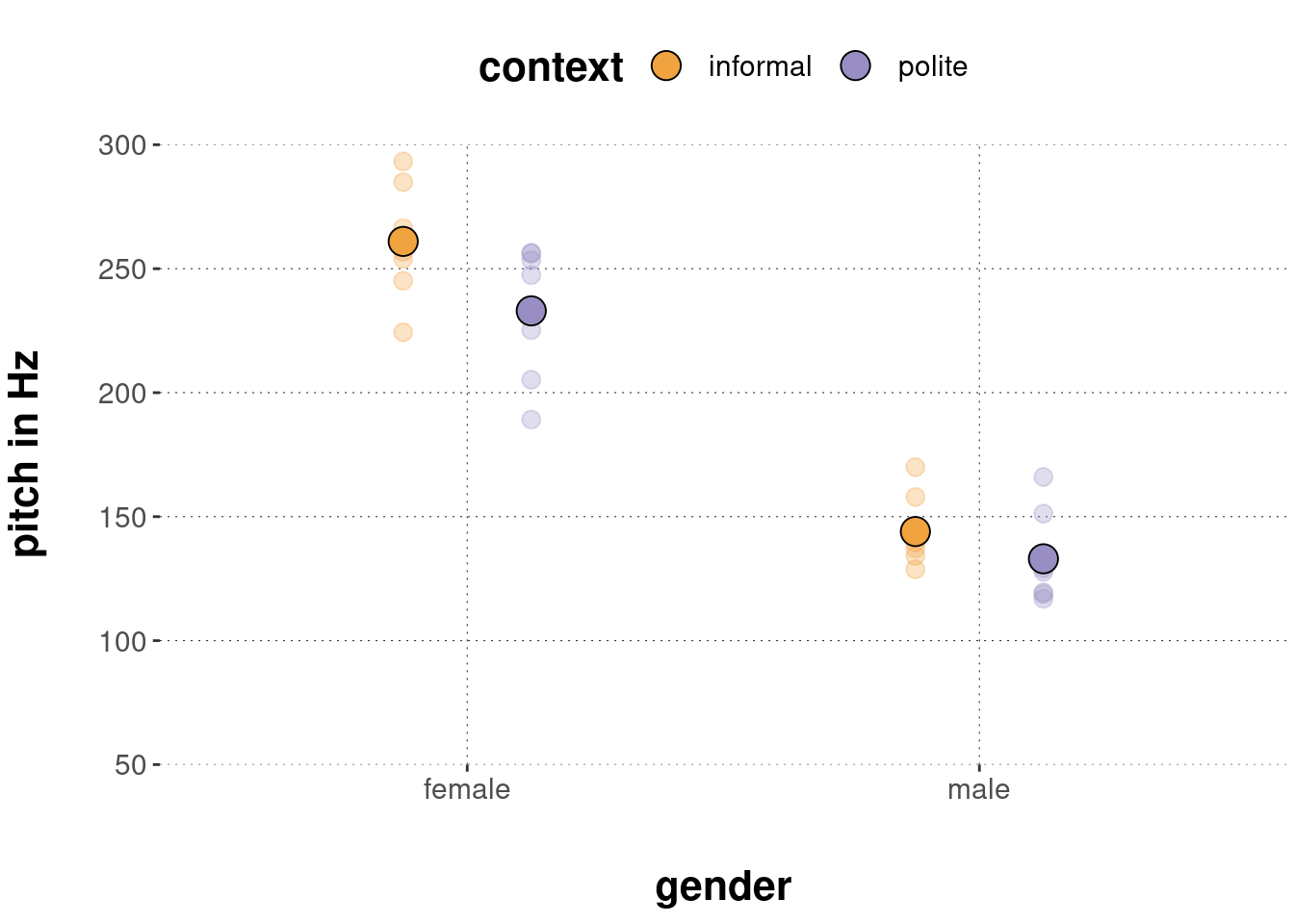
The data set contains measurements of voice pitch obtained from a \(2 \times 2\) factorial design, with factors gender and context.
The data is from Korean speakers.
Here is a glimpse of the data:
politeness_data <- aida::data_polite
glimpse(politeness_data)## Rows: 83
## Columns: 5
## $ subject <chr> "F1", "F1", "F1", "F1", "F1", "F1", "F1", "F1", "F1", "F1", "…
## $ gender <chr> "F", "F", "F", "F", "F", "F", "F", "F", "F", "F", "F", "F", "…
## $ sentence <chr> "S1", "S1", "S2", "S2", "S3", "S3", "S4", "S4", "S5", "S5", "…
## $ context <chr> "pol", "inf", "pol", "inf", "pol", "inf", "pol", "inf", "pol"…
## $ pitch <dbl> 213.3, 204.5, 285.1, 259.7, 203.9, 286.9, 250.8, 276.8, 231.9…The variables contained here are:
subject: an indicator for each experimental participantgender: an indicator of each participants gender (only binary)sentence: an indicator of the sentence spoken by the participantcontext: the main manipulation of whether the context was a “polite” or “informal” settingpitch: the measured voice pitch (presumably: average over the sentence spoken)
D.8.2 Hypotheses
The main research question of interest here is whether voice pitch is higher in “polite” contexts than in “informal”, and whether this effect is more or less present for male or female speakers.
References
Franke, Michael, and Timo B. Roettger. 2019. “Bayesian Regression Modeling (for Factorial Designs): A Tutorial.”
Winter, Bodo. 2013. “Linear models and linear mixed effects models in R with linguistic applications.”
Winter, Bodo, and S. Grawunder. 2012. “The Phonetic Profile of Korean Formality.” Journal of Phonetics 40: 808–15.