The term “distributional model” is not sharply defined and not altogether common. Alternatively, one may read “models for location, scale and shape” or similar verbiage. The general idea, however, is simple: when our model has a likelihood function with additional parameters, e.g., the standard deviation \(\sigma\) in the Gaussian likelihood function of a vanilla linear regression, we can not only infer these parameters, but also make them dependent, e.g., on other predictors.
For example, when a standard linear regression model would look like this:
thereby assuming that \(\sigma\) itself depends on the predictors \(X\) in a linear way.
Preamble
Here is code to load (and if necessary, install) required packages, and to set some global options (for plotting and efficient fitting of Bayesian models).
Toggle code
# install packages from CRAN (unless installed)pckgs_needed <-c("tidyverse","brms","rstan","rstanarm","remotes","tidybayes","bridgesampling","shinystan","mgcv")pckgs_installed <-installed.packages()[,"Package"]pckgs_2_install <- pckgs_needed[!(pckgs_needed %in% pckgs_installed)]if(length(pckgs_2_install)) {install.packages(pckgs_2_install)} # install additional packages from GitHub (unless installed)if (!"aida"%in% pckgs_installed) { remotes::install_github("michael-franke/aida-package")}if (!"faintr"%in% pckgs_installed) { remotes::install_github("michael-franke/faintr")}if (!"cspplot"%in% pckgs_installed) { remotes::install_github("CogSciPrag/cspplot")}# load the required packagesx <-lapply(pckgs_needed, library, character.only =TRUE)library(aida)library(faintr)library(cspplot)# these options help Stan run fasteroptions(mc.cores = parallel::detectCores())# use the CSP-theme for plottingtheme_set(theme_csp())# global color scheme from CSPproject_colors = cspplot::list_colors() |>pull(hex)# names(project_colors) <- cspplot::list_colors() |> pull(name)# setting theme colors globallyscale_colour_discrete <-function(...) {scale_colour_manual(..., values = project_colors)}scale_fill_discrete <-function(...) {scale_fill_manual(..., values = project_colors)}
Example: World temperature data
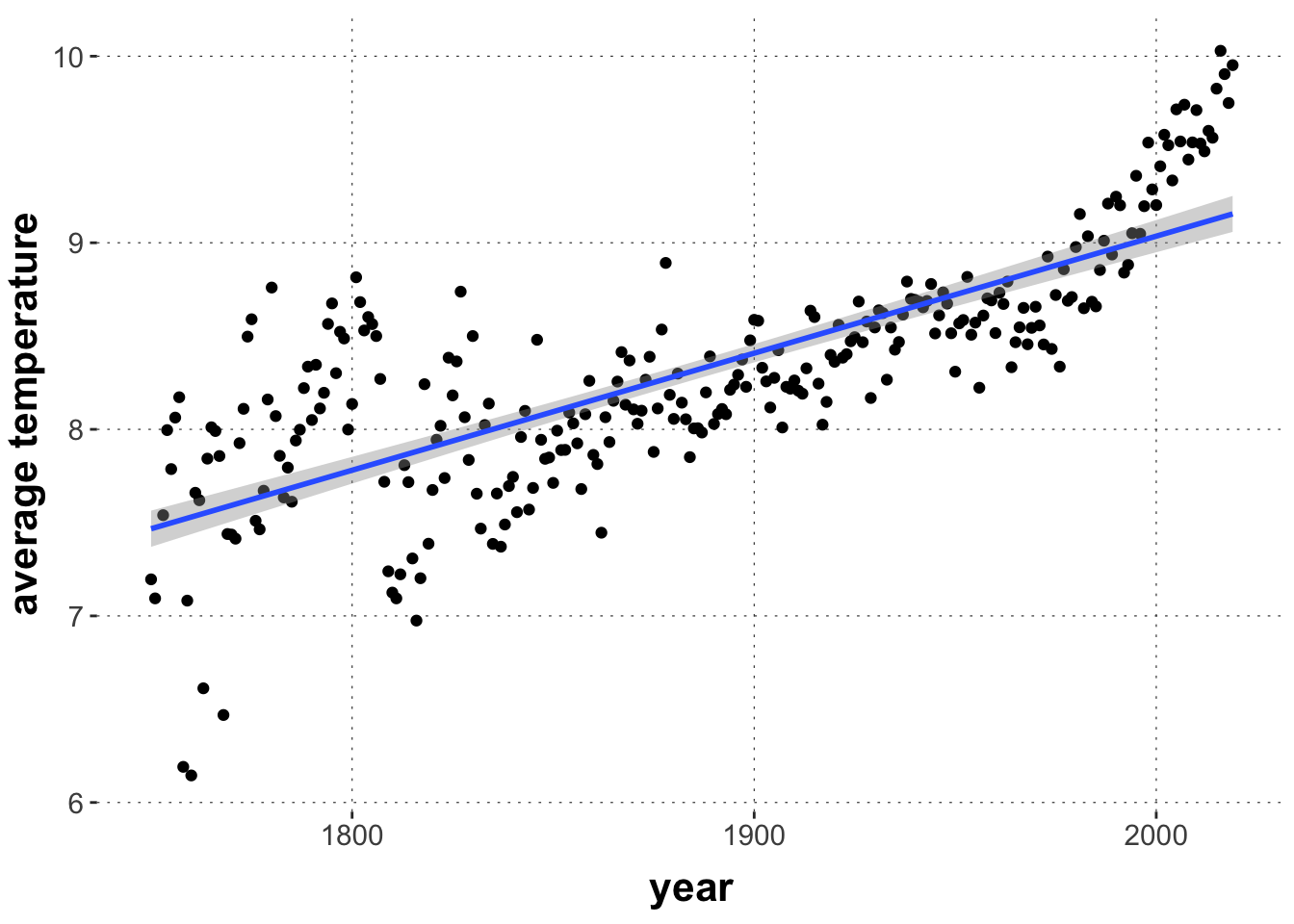
The World Temperature data, included in the aida package provides a useful minimal example. We want to regress avg_temp on year, but we see that early measurements appear to be much more noisy, so that a linear fit will be better for data between 1900 and 1980, and worse for data between 1750 to 1900, simply because of differences related to differently noise measurements at different times.
But there are clear indicators that this is not a very good model, e.g., using a posterior predictive \(p\)-value with the standard deviation for predictions of all data points between 1750-1800 as a test statistic:
If we care about faithful prediction in this early period, including accuracy about the noisiness of the data, the vanilla linear model is clearly bad.
A simple distributional model
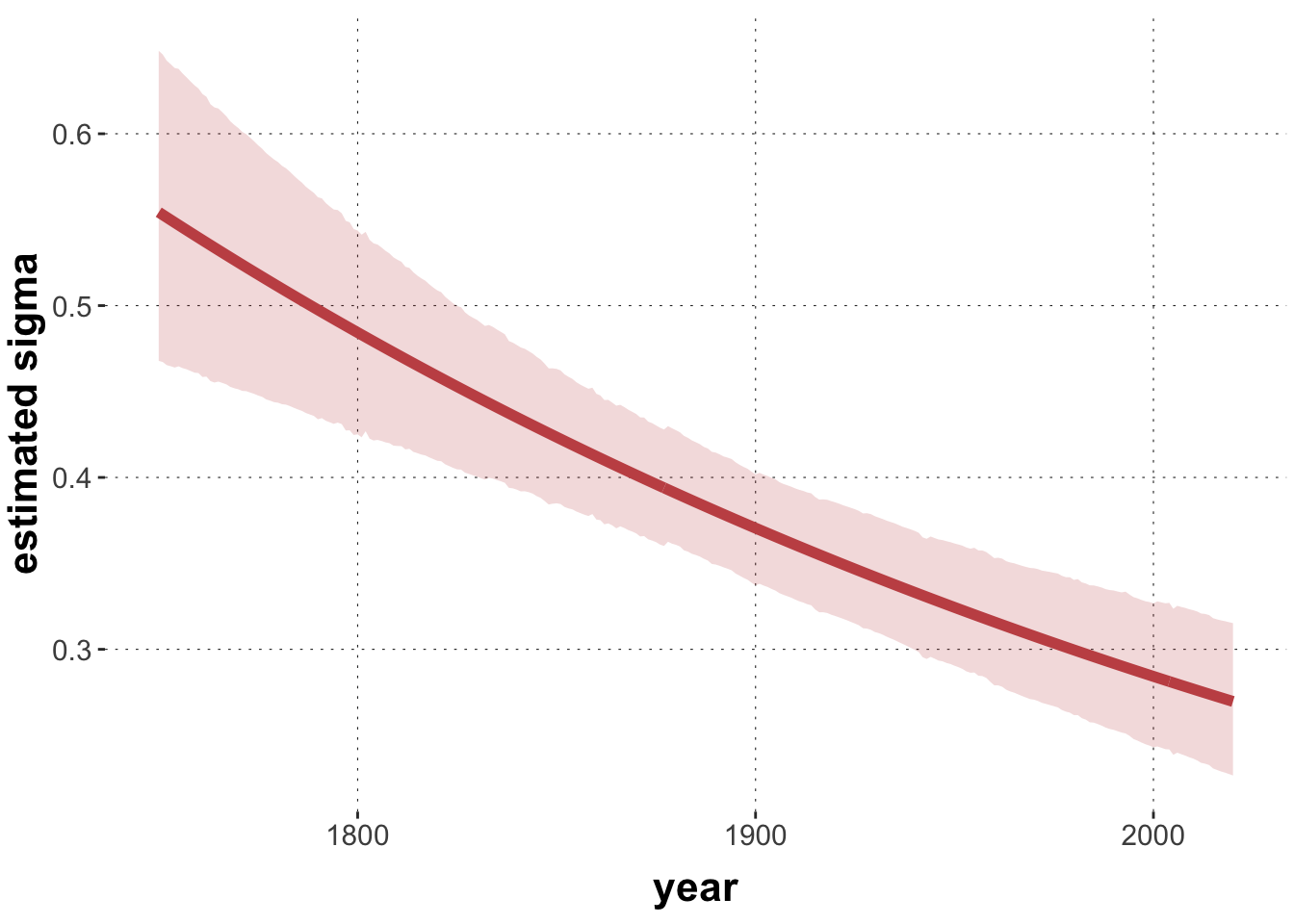
We want to fit the distributional model sketched in the beginning:
This formula first declares that avg_temp is to be regressed on year, as usual, and also declares that sigma is supposed to be regressed (in quite the same way) on year as well. The variable sigma does not occur in the data, but is recognized as an internal variable, namely the standard deviation of the Gaussian likelihood function.
Sampling with Stan can get troublesome if parameters are on quite different scales, so we should make sure that the two estimands are roughly on the same scale.
Toggle code
# to run a distributional model, we need to rescale 'year'# division by a factor of 1000 is sufficientdata_WorldTemp <- aida::data_WorldTemp |>mutate(year = (year)/1000)
prior class coef group resp dpar nlpar lb ub
student_t(3, 8.3, 2.5) Intercept
(flat) b
(flat) b year
student_t(3, 0, 2.5) Intercept sigma
(flat) b sigma
(flat) b year sigma
source
default
default
(vectorized)
default
default
(vectorized)
Using this information set a prior on the slope coefficient for both components of the model. Use a Student-t distribution with one degree of freedom, mean 0 and standard deviation 10.
Solution
Toggle code
prior_temp_distributional <-c(prior(student_t(1,0,10), class ="b", coef ="year_c"),prior(student_t(1,0,10), class ="b", dpar ="sigma") )