Sheet 4.2: Non-linear regression (MLP w/ PyTorch modules)#
Author: Michael Franke
In this tutorial, we will fit a non-linear regression, implemented as a multi-layer perceptron. We will see how the use of modules from PyTorch’s neural network package `torch.nn` helps us implement the model efficiently.
Packages & global parameters#
We will need to import the `torch` package for the main functionality. In addition to the previous sheet, In order to have a convenient, we will use PyTorch’s `DataLoader` and `Dataset` in order to feed our training data to the model.
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import DataLoader
from torch.utils.data import Dataset
import numpy as np
import seaborn as sns
import pandas as pd
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings('ignore')
True model & training data#
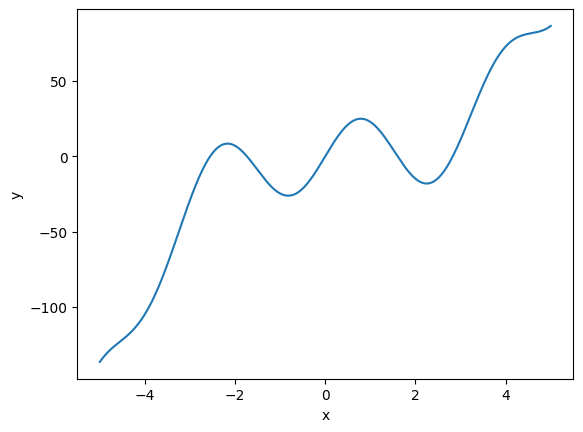
The “true model” is a constructed non-linear function \(y = f(x)\). Here is its definition and a plot to show what the “ground truth” looks like.
##################################################
## ground-truth model
##################################################
def goalFun(x):
return(x**3 - x**2 + 25 * np.sin(2*x))
# create linear sequence (x) and apply goalFun (y)
x = np.linspace(start = -5, stop =5, num = 1000)
y = goalFun(x)
# plot the function
d = pd.DataFrame({'x' : x, 'y' : y})
sns.lineplot(data = d, x = 'x', y = 'y')
plt.show()
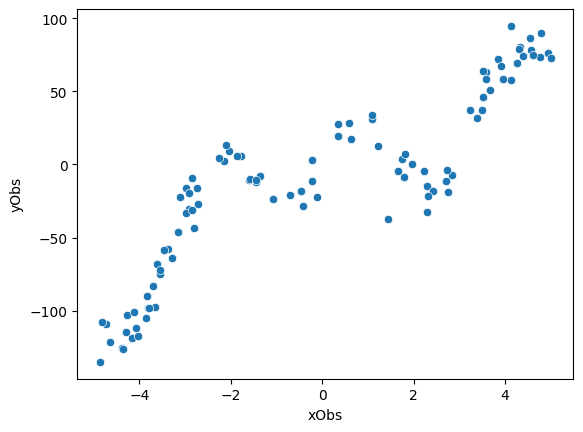
The training data consists of 100 pairs of \((x,y)\) values. Each pair is generated by first sampling an \(x\) value from a uniform distribution. For each sampled \(x\), we compute the value of the target function \(f(x)\) and add Gaussian noise to it.
##################################################
## generate training data (with noise)
##################################################
nObs = 100 # number of observations
# get noise around y observations
yNormal = torch.distributions.Normal(loc=0.0, scale=10)
yNoise = yNormal.sample([nObs])
# get observations
xObs = 10*torch.rand([nObs])-5 # uniform from [-5,5]
yObs = xObs**3 - xObs**2 + 25 * torch.sin(2*xObs) + yNoise
# plot the data
d = pd.DataFrame({'xObs' : xObs, 'yObs' : yObs})
sns.scatterplot(data = d, x = 'xObs', y = 'yObs')
plt.show()
Defining the MLP using PyTorch’s built-in modules#
As before (sheet 4.1), our model maps a single scalar \(x\) onto another scalar \(y\). We use a 3-layer MLP, each hidden layer with dimension 10:
##################################################
## network dimension parameters
##################################################
nInput = 1
nHidden = 10
nOutput = 1
PyTorch defines a special-purpose class called `nn.Module` from which pre-defined neural networks or custom-made networks inherit the structure and basic functionality. Below, we define our feed-forward neural network as a class extending `nn.Module`. Minimally, we have to define two functions for this to work:
the initialization function `_init__` which defines which variables (mostly, but not exclusively: parameters) our model has (using `nn.Linear` instantiates a linear layer with all the trainable parameters (weights and biases) implicitly);
the forward pass which takes the model’s input and computes the corresponding prediction given the current parameter values (recall the function `singleForwardPass` from sheet 4.1; PyTorch automatically batches the computation implicitly).
Since PyTorch allows flexibility in how to define neural network modules, we look at two variants below, one explicit and one more concise. They should implement the exact same model and work the same way eventually.
More explicit definition NN module#
##################################################
## set up multi-layer perceptron w/ PyTorch
## -- explicit version --
##################################################
class MLPexplicit(nn.Module):
'''
Multi-layer perceptron for non-linear regression.
'''
def __init__(self, nInput, nHidden, nOutput):
super(MLPexplicit, self).__init__()
self.nInput = nInput
self.nHidden = nHidden
self.nOutput = nOutput
self.linear1 = nn.Linear(self.nInput, self.nHidden)
self.linear2 = nn.Linear(self.nHidden, self.nHidden)
self.linear3 = nn.Linear(self.nHidden, self.nHidden)
self.linear4 = nn.Linear(self.nHidden, self.nOutput)
self.ReLU = nn.ReLU()
def forward(self, x):
h1 = self.ReLU(self.linear1(x))
h2 = self.ReLU(self.linear2(h1))
h3 = self.ReLU(self.linear3(h2))
output = self.linear4(h3)
return(output)
mlpExplicit = MLPexplicit(nInput, nHidden, nOutput)
We can access the current parameter values of this model instance like so:
for p in mlpExplicit.parameters():
print(p.detach().numpy().round(4))
#+begin_example
[[-0.3159]
[-0.9458]
[ 0.7417]
[-0.4918]
[-0.6417]
[ 0.9118]
[-0.4813]
[-0.3574]
[ 0.1918]
[-0.1202]]
[ 0.199 0.5661 -0.0536 0.4207 0.5063 -0.0844 0.3078 -0.8431 -0.9134
0.8743]
[[ 0.0681 -0.1082 -0.3003 -0.2709 0.2579 0.0048 -0.2063 0.1746 -0.068
0.278 ]
[-0.2888 -0.3092 -0.2151 -0.2614 -0.204 0.0504 0.31 0.0173 0.1955
-0.2616]
[ 0.1086 -0.1308 0.023 -0.2852 0.1416 -0.2045 0.1567 -0.2506 -0.1606
-0.2072]
[-0.0156 -0.2017 -0.2975 -0.3103 -0.2067 -0.272 -0.266 0.2946 0.0607
0.1012]
[-0.2783 0.2013 -0.023 -0.1788 -0.1047 0.0859 -0.0007 0.2166 -0.2216
0.2166]
[-0.0781 0.1222 -0.1383 0.0901 -0.0528 0.0843 0.1695 -0.2518 0.0599
-0.1314]
[-0.269 0.0332 -0.1462 -0.1037 0.1216 0.1081 -0.2924 0.0238 -0.1814
-0.1739]
[ 0.0869 -0.075 -0.0435 0.1514 0.0998 0.1542 -0.1037 -0.024 0.1347
0.0108]
[ 0.0037 0.0187 0.2528 0.198 -0.2122 0.1342 0.3033 0.0299 0.1761
-0.1406]
[ 0.2971 0.2727 0.0964 0.2299 0.1205 0.3082 0.2623 0.095 0.1824
0.1422]]
[-0.0146 -0.2674 -0.0453 -0.2229 -0.069 -0.0381 -0.0619 -0.1094 0.1782
-0.1518]
[[-0.1355 -0.1274 0.0702 -0.1417 0.1605 0.1512 0.2732 0.007 -0.0946
0.0078]
[ 0.3127 -0.1178 0.0105 -0.0098 0.1161 -0.2215 -0.1687 0.1658 -0.0911
-0.1003]
[-0.1051 0.0553 -0.1223 -0.2143 0.0522 0.0445 -0.1558 -0.1047 -0.0466
-0.209 ]
[-0.1886 0.0218 -0.1924 -0.2613 -0.2529 0.1264 -0.0761 -0.3144 -0.2352
0.273 ]
[ 0.0039 -0.3057 -0.1822 -0.0795 -0.0463 -0.2428 0.0715 -0.299 -0.1077
-0.0445]
[ 0.1704 -0.1093 -0.2946 -0.0789 -0.0541 0.0837 -0.1497 -0.306 0.0315
-0.1734]
[-0.1813 -0.1971 -0.1675 0.149 -0.1458 -0.0889 0.242 0.0492 0.197
-0.2445]
[-0.0319 0.0896 0.1942 -0.2389 -0.2825 0.0941 0.1893 -0.1406 0.0355
-0.2501]
[-0.0749 -0.0727 0.2973 0.3098 -0.2146 0.191 0.2544 -0.1775 -0.304
-0.2993]
[-0.0056 0.2573 -0.1527 0.011 0.2042 0.1477 -0.1644 -0.0734 0.272
0.0188]]
[ 0.2291 -0.1599 -0.0373 -0.1247 -0.3078 0.0436 0.0384 -0.1144 0.0929
-0.3155]
[[-0.0842 0.1034 -0.3088 0.273 0.058 -0.1163 -0.0321 0.2645 -0.0852
0.2957]]
[0.0191]
#+end_example
Exercise 4.2.1: Inspect the model’s parameters and their initial values
[Just for yourself.] Make sure that you understand what these parameters are by mapping these onto the parameters of the custom-made model from sheet 4.1. (Hint: the order of the presentation in this print-out is the order in which the components occur in the computation of the forward pass.)
Guess how the weights of the slope matrices are initialized (roughly). Same for the intercept vectors.
More concise definition of NN module#
Here is another, more condensed definition of the same NN model, which uses the `nn.Sequantial` function to neatly chain components, thus defining the model parameters and the forward pass in one swoop.
##################################################
## set up multi-layer perceptron w/ PyTorch
## -- condensed version --
##################################################
class MLPcondensed(nn.Module):
'''
Multi-layer perceptron for non-linear regression.
'''
def __init__(self, nInput, nHidden, nOutput):
super().__init__()
self.layers = nn.Sequential(
nn.Linear(nInput, nHidden),
nn.ReLU(),
nn.Linear(nHidden, nHidden),
nn.ReLU(),
nn.Linear(nHidden, nHidden),
nn.ReLU(),
nn.Linear(nHidden, nOutput)
)
def forward(self, x):
return(self.layers(x))
mlpCondensed = MLPcondensed(nInput, nHidden, nOutput)
Here you can select which one to use in the following.
# which model to use from here onwards
# model = mlpExplicit
model = mlpCondensed
Preparing the training data#
Data pre-processing is a tedious job, but an integral part of machine learning. In order to have a clean interface between data processing and modeling, we would ideally like to have a common data format to feed data into any kind of model. That also makes sharing and reusing data sets much less painful. For this purpose, PyTorch provides two data primitives: `torch.utils.data.Dataset` and `torch.utils.data.DataLoader`. The class Dataset stores the training data (in a reusable format). The class DataLoader takes a `dataset` object as input and returns an iterable to enable easy access to the training data.
To define a `Dataset` object, we have to specify two key functions:
the `_len__` function, which tells subsequent applications how many data points there are; and
the `_getitem__` function, which takes an index as input and outputs the data point corresponding to that index.
##################################################
## representing train data as a Dataset object
##################################################
class nonLinearRegressionData(Dataset):
'''
Custom 'Dataset' object for our regression data.
Must implement these functions: __init__, __len__, and __getitem__.
'''
def __init__(self, xObs, yObs):
self.xObs = torch.reshape(xObs, (len(xObs), 1))
self.yObs = torch.reshape(yObs, (len(yObs), 1))
def __len__(self):
return(len(self.xObs))
def __getitem__(self, idx):
return(xObs[idx], yObs[idx])
# instantiate Dataset object for current training data
d = nonLinearRegressionData(xObs, yObs)
# instantiate DataLoader
# we use the 4 batches of 25 observations each (full data has 100 observations)
# we also shuffle the data
train_dataloader = DataLoader(d, batch_size=25 , shuffle=True)
We can test the iterable that we create, just to inspect how the data will be delivered later on:
for i, data in enumerate(train_dataloader, 0):
input, target = data
print("In: ", input)
print("Out:", target,"\n")
#+begin_example
In: tensor([ 1.6464, 1.4377, 1.0789, 4.3370, 2.3034, -2.7963, 4.1376, -4.2736,
2.2943, -1.4434, 0.3546, 0.5746, -1.3677, -2.1517, -3.1494, -1.0780,
1.0905, -1.5783, 4.5666, -3.6602, 2.7474, 3.8391, 3.9052, -3.7125,
3.5169])
Out: tensor([ -4.6213, -37.1629, 33.7094, 80.5609, -21.5217, -43.7430,
94.8257, -103.0323, -14.7449, -10.7285, 27.8033, 28.4946,
-7.5583, 2.6049, -46.0016, -23.8963, 31.1297, -10.0781,
78.0105, -97.6725, -18.6345, 72.5226, 67.0642, -83.2561,
46.0740])
In: tensor([ 2.7017, -1.4519, 3.3762, -1.8632, -3.1052, -4.8659, -2.9799, -4.3782,
-0.1090, -4.0703, -4.1712, 3.2352, 4.1348, 2.2157, 0.3464, 4.9987,
-3.6174, 0.6203, -4.6460, -4.0361, 3.9621, -4.7405, 2.4142, -3.5388,
-0.2195])
Out: tensor([ -10.9952, -11.8348, 31.7845, 5.5263, -22.1953, -135.1510,
-33.4469, -125.7038, -21.9528, -111.9567, -118.6303, 37.3962,
58.1187, -4.3078, 19.1822, 72.9351, -68.3588, 17.2424,
-121.6277, -117.2821, 58.3159, -109.3604, -18.1771, -72.1463,
3.0245])
In: tensor([ 4.6001, -2.8408, -2.0477, -2.9867, -3.3673, 4.7615, 3.5257, -4.3663,
3.6740, -3.4726, 1.7471, 4.3816, 4.7928, -2.9165, -2.2658, -0.2160,
-3.4545, -4.3007, -2.8524, 1.8128, 4.3026, 1.9636, -0.6963, -1.7744,
-2.1021])
Out: tensor([ 74.9118, -9.2894, 9.2732, -15.7943, -58.0797, 73.8717,
63.7752, -126.1213, 51.1963, -58.6351, 3.7010, 74.3381,
90.1596, -30.6364, 4.2229, -11.4130, -58.7030, -114.3573,
-31.1926, 6.8666, 79.0198, 0.3651, -20.7417, 6.0864,
12.9824])
In: tensor([ 4.9336, -2.7347, -0.4259, 1.7787, 4.2678, 3.4991, 4.5461, -4.8106,
-3.8359, -3.2760, 1.2288, -3.7825, -0.4579, 2.7253, -1.6002, -2.9198,
2.2854, 3.5805, -3.5451, -3.8535, 3.5728, -4.1084, -2.7085, 2.8383,
-3.8190])
Out: tensor([ 76.3138, -16.2862, -28.3352, -8.6570, 69.5087, 37.1587,
86.3992, -107.7773, -90.2492, -64.2161, 12.6987, -98.3395,
-18.3555, -3.7175, -10.7333, -19.5029, -32.6816, 63.0212,
-75.0719, -105.0783, 58.8076, -101.1572, -26.8450, -6.9867,
-98.2746])
#+end_example
Training the model#
We can now train the model similar to how we did this before. Note that we need to slightly reshape the input data to have the model compute the batched input correctly.
##################################################
## training the model
##################################################
# Define the loss function and optimizer
loss_function = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=1e-4)
nTrainSteps = 50000
# Run the training loop
for epoch in range(0, nTrainSteps):
# Set current loss value
current_loss = 0.0
# Iterate over the DataLoader for training data
for i, data in enumerate(train_dataloader, 0):
# Get inputs
inputs, targets = data
# Zero the gradients
optimizer.zero_grad()
# Perform forward pass (make sure to supply the input in the right way)
outputs = model(torch.reshape(inputs, (len(inputs), 1))).squeeze()
# Compute loss
loss = loss_function(outputs, targets)
# Perform backward pass
loss.backward()
# Perform optimization
optimizer.step()
# Print statistics
current_loss += loss.item()
if (epoch + 1) % 2500 == 0:
print('Loss after epoch %5d: %.3f' %
(epoch + 1, current_loss))
current_loss = 0.0
# Process is complete.
print('Training process has finished.')
yPred = np.array([model.forward(torch.tensor([o])).detach().numpy() for o in xObs]).flatten()
# plot the data
d = pd.DataFrame({'xObs' : xObs.detach().numpy(),
'yObs' : yObs.detach().numpy(),
'yPred': yPred})
dWide = pd.melt(d, id_vars = 'xObs', value_vars= ['yObs', 'yPred'])
sns.scatterplot(data = dWide, x = 'xObs', y = 'value', hue = 'variable', alpha = 0.7)
x = np.linspace(start = -5, stop =5, num = 1000)
y = goalFun(x)
plt.plot(x,y, color='g', alpha = 0.5)
plt.show()
#+begin_example
Loss after epoch 2500: 3388.350
Loss after epoch 5000: 2624.341
Loss after epoch 7500: 1626.610
Loss after epoch 10000: 1134.846
Loss after epoch 12500: 811.041
Loss after epoch 15000: 624.522
Loss after epoch 17500: 544.807
Loss after epoch 20000: 502.190
Loss after epoch 22500: 477.270
Loss after epoch 25000: 456.302
Loss after epoch 27500: 437.854
Loss after epoch 30000: 421.832
Loss after epoch 32500: 408.325
Loss after epoch 35000: 397.359
Loss after epoch 37500: 388.589
Loss after epoch 40000: 382.442
Loss after epoch 42500: 378.091
Loss after epoch 45000: 373.392
Loss after epoch 47500: 369.820
Loss after epoch 50000: 367.238
Training process has finished.
#+end_example
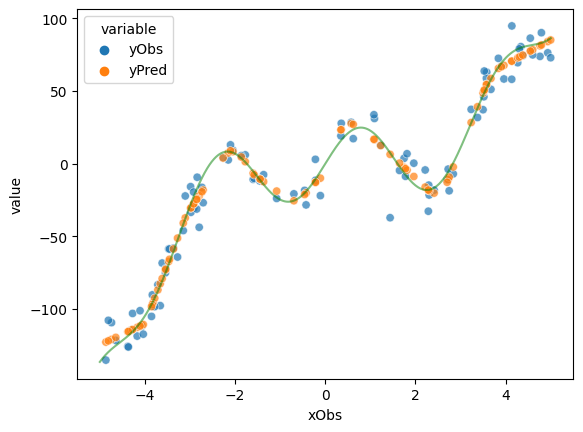
Exercise 4.2.2: Explore the model’s behavior
[Just for yourself.] Make sure you understand every line in this last code block. Ask if anything is unclear.
Above we used the DataLoader to train in 4 mini-batches. Change it so that there is only one batch containing all the data. Change the `shuffle` parameter so that data is not shuffled. Run the model and check if you observe any notable differences. Explain what your observations. (If you do not see anything, explain why you don’t. You might pay attention to the results of training)