Bayesian data analysis
Appendix chapter 03: Bayesian data analysis for the RSA reference game model
Author: Michael Franke
WebPPL allows us to conveniently specify even complex probabilistic cognitive models and to explore the predictions these models make. Usually these predictions are probabilistic. For example, the RSA model might predict that the probability that a pragmatic listener assigns to interpretation after hearing utterance is . Sometimes it suffices for our explanatory purposes to just obtain such (probabilistic) predictions. For example, we might want to explain that the listener’s assumptions about the speaker’s knowledge impact conclusions about scalar implicatures in a particular qualitative but systematic way (see Chapter 2). Sometimes, however, our explanatory ambitions are more adventurous. Sometimes we like to explain quantitative data, e.g., from observational experiments or corpora. In this case, WebPPL makes it easy to analyse our experimental data through the lens of our probabilistic cognitive models; or, put more strikingly, it allows us to reason about various relevant unknowns based on the data observed. Relevant unknowns include (i) model parameters, (ii) future observations and (iii) models, hypotheses or theories themselves. In this chapter we will therefore look briefly at the three pillars of Bayesian data analysis:
- parameter estimation where we infer which values of model parameters are likely given the observed data;
- model criticism where we ask whether the current model is a good enough model for the data at hand;
- model comparison where we ask what relative evidence the data provides for one model over another.
Motivating example
Consider the vanilla RSA model from Chapter 1 once more. The model is intended to explain data from reference games, such as pictured in Fig. 1.

The vanilla RSA model defines a literal and a pragmatic listener rule, both of which map utterances to probability distributions over states/objects :
Let us use the code below to look at how literal and pragmatic listeners would interpret the utterance “blue” for the example from Chapter 1. (The predictions for the pragmatic listener depend on the optimization parameter . It is here set to . We will come back to this below.)
// Frank and Goodman (2012) RSA model
// set of states (here: objects of reference)
var states = ["blue_circle", "green_square", "blue_square"]
// set of utterances
var utterances = ["blue","green","square","circle"]
// prior over world states
var objectPrior = function() {
uniformDraw(states)
}
// meaning function to interpret the utterances
var meaning = function(utterance, obj){
_.includes(obj, utterance)
}
// literal listener
var literalListener = function(utterance){
Infer({model: function(){
var obj = objectPrior();
condition(meaning(utterance, obj))
return obj
}})
}
// set speaker optimality
var alpha = 1
// pragmatic speaker
var speaker = function(obj){
Infer({model: function(){
var utterance = uniformDraw(utterances)
factor(alpha * literalListener(utterance).score(obj))
return utterance
}})
}
// pragmatic listener
var pragmaticListener = function(utterance){
Infer({model: function(){
var obj = objectPrior()
observe(speaker(obj),utterance)
return obj
}})
}
display("Literal listener's interpretation of 'blue':")
viz.table(literalListener("blue"))
display("Pragmatic listener's interpretation of 'blue':")
viz.table(pragmaticListener("blue"))
Suppose we conducted a simple experiment in which we provide the referential context in Fig. 1 above and ask human participants to choose the object of which they believe that a speaker meant who chose utterance “blue”. The experiment of reft:frankgoodman2012 was slightly different (a betting paradigm in which participants had to distribute 100 points over the potential referents), but reft:QingFranke2013:Variations-on-a executed exactly such a forced choice experiment, in which each participant had to choose exactly one referent. They observed that in all conditions structurally equivalent to an observation of utterance “blue” in the context of Fig. 1, 115 participants chose the blue square and 65 chose the blue circle, while nobody (phew!) chose the green square.
var comp_data = {
blue: {blue_circle: 65, green_square: 0, blue_square: 115},
}
What can we do with this data and our model? - Generally, a lot! Much depends on what we want. We could summon classical statistics, for example, to test whether an observation of 115 successes in 115+65 = 180 trials is surprising under a null hypothesis that assumes, like a literal listener model does, that successes and failures are equally likely. Indeed, a binomial test gives a highly significant result (), which is standardly interpreted as an indication that the null hypothesis is to be rejected. In our case this means that it is highly unlikely that the data observed was generated by a literal listener model.
Bayesian data analysis is different from classical hypothesis testing. From a Bayesian point of view, we rather ask: how likely is it that the literal listener model or the pragmatic listener model has generated the observed results? Suppose that we are initially completely undecided about which model is likely correct, but (for the sake of a simple example) consider only those two listener models. Then our prior belief in each model is equal , where and are the literal and pragmatic listener model, respectively. Our posterior belief after observing data concerning the probability of can be calculated by Bayes rule:
Since prior beliefs are equal, they cancel out, leaving us with:
The remaining terms are of the form and refer to the likelihood of the data under each model, i.e., how likely the actually observed data was from each model’s point of view. We can easily calculate them in WebPPL and retrive the corresponding posterior beliefs:
var total_observations = 180
var observed_successes = 115
var LH_literalLister = Math.exp(Binomial({n: total_observations,
p: 0.5}).score(observed_successes))
var LH_pragmatLister = Math.exp(Binomial({n: total_observations,
p: 0.6}).score(observed_successes))
var posterior_literalListener = LH_literalLister /
(LH_literalLister + LH_pragmatLister)
display(posterior_literalListener)
Exercises:
- What is the probability of the pragmatic listener model given the data?
- How much more likely is the pragmatic listener model than the literal listener model, given the data?
- Play around with different values for
observed_successes. For which of these will the literal listener model be more likely?- Play around with different values for
total_observations. What happens to our beliefs if we observe more data rather than less, while keeping the ratio betweentotal_observationsandobserved_successesthe same? (Just multiply bothtotal_observationsandobserved_successeswith the same factor to explore this.)
Parameter estimation
Above we compared two models, each of which made exact (probabilistic) predictions (i.e., 0.5 vs 0.6).
If we consider the pragmatic listener more closely, we realize that there is more than just one pragmatic listener model but many, each one corresponding to a different value of .
In fact, as , the pragmatic listener model makes the same predictions as the literal listener model.
So, the literal listener model can be seen as a special case of the pragmatic listener, when .
To convince yourself of this, go to the RSA model below—in which alpha is now an argument to the pragmaticListener function—and run it by setting alpha to different values.
// Frank and Goodman (2012) RSA model
// set of states (here: objects of reference)
var states = ["blue_circle", "green_square", "blue_square"]
// set of utterances
var utterances = ["blue","green","square","circle"]
// prior over world states
var objectPrior = function() {
uniformDraw(states)
}
// meaning function to interpret the utterances
var meaning = function(utterance, obj){
_.includes(obj, utterance)
}
// literal listener
var literalListener = function(utterance){
Infer({model: function(){
var obj = objectPrior();
condition(meaning(utterance, obj))
return obj
}})
}
// pragmatic speaker
var speaker = function(obj, alpha){ //alpha is now an argument
Infer({model: function(){
var utterance = uniformDraw(utterances)
factor(alpha * literalListener(utterance).score(obj))
return utterance
}})
}
// pragmatic listener
var pragmaticListener = function(utterance, alpha){ //alpha is now an argument
Infer({model: function(){
var obj = objectPrior()
observe(speaker(obj, alpha),utterance) // pass alpha to the speaker function
return obj
}})
}
display("Literal listener's interpretation of 'blue':")
viz.table(literalListener("blue"))
display("Pragmatic listener's interpretation of 'blue':")
viz.table(pragmaticListener("blue", 1)) // we now need to supply alpha here
Exercises:
- Check that gives predictions identical to the literal listener’s rule.
- What happens if we feed in ? Why is this happening?
In a sense, we now have infinitely many models, one for each value of . Another equivalent way of looking at this is to say that we have one model whose probabilistic predictions depend on the value of the parameter . In other words, we have defined a parameterized likelihood function for observational data . Whenever it is clear what the model is, we can drop the reference to the model from our notation. For the general case of possibly high-dimensional continuous parameter vector , we can use Bayes rule for parameter inference like so:
For complex models with unwieldy parameter spaces, the above formula can quickly become intractable. The problem is in the normalizing constant, the so-called marginal likelihood. (“Likelihood” because we sum over, so to speak, the likelihood of the data; “marginal” because we marginalize over (think: compute a probability-weighted sum over) all parameter values.) But even if the above is not calculable with a single precise mathematical formula, there are ways of obtaining samples from the posterior distribution which do not require knowledge of an easily computable representation of the marginal likelihood. Markov Chain Monte Carlo (MCMC) methods are a family of algorithms that provide this. Concretely, MCMC methods provide a clever and efficient way of generating samples from by using only the non-normalized posterior scores, i.e., the product of prior and likelihood at a single parameter value , which is usually very fast and easy to compute (at least relative to the integral needed for the marginal likelihood):
Notice that sampling-based approximations of probability distributions are at the heart of probabilistic programming, Consequently, WebPPL has functionality for MCMC-driven inference built in. To allow the computation of samples from the posterior over optimality parameter in our simple running example, we need to define a function (see code box below) which basically implements the non-normalized posterior scores of the last formula above, in such a way that WebPPL understands what is what:
// Frank and Goodman (2012) RSA model
///fold:
// set of states (here: objects of reference)
var states = ["blue_circle", "green_square", "blue_square"]
// set of utterances
var utterances = ["blue","green","square","circle"]
// prior over world states
var objectPrior = function() {
uniformDraw(states)
}
// meaning function to interpret the utterances
var meaning = function(utterance, obj){
_.includes(obj, utterance)
}
// literal listener
var literalListener = function(utterance){
Infer({model: function(){
var obj = objectPrior();
condition(meaning(utterance, obj))
return obj
}})
}
// pragmatic speaker
var speaker = function(obj, alpha){ //alpha is now an argument
Infer({model: function(){
var utterance = uniformDraw(utterances)
factor(alpha * literalListener(utterance).score(obj))
return utterance
}})
}
// pragmatic listener
var pragmaticListener = function(utterance, alpha){ //alpha is now an argument
Infer({model: function(){
var obj = objectPrior()
observe(speaker(obj, alpha),utterance) // pass alpha to the speaker function
return obj
}})
}
///
// Data analysis
var non_normalized_posterior = function(){
// prior over model parameter
var alpha = uniform({a:0, b:10})
var predicted_probability =
Math.exp(
pragmaticListener("blue", alpha).score("blue_square")
)
var likelihood = Binomial({n: 180, p: predicted_probability}).score(115)
factor(likelihood)
return {alpha}
}
var posterior_samples = Infer({
method: "MCMC",
samples: 10000, // how many samples to obtain
burn: 1500, // number of steps for algorithm to adapt
model: non_normalized_posterior})
viz(posterior_samples)
Exercises:
- Looking at the density plot that results from this computation, which region of values is most likely given the data?
- Are the special cases of and competitive, or are they very clearly much worse than the “best values”?
- Bayesian posterior inference depends on the specification of a prior over parameters. The above code originally uses a uniform prior over :
var alpha = uniform({a:0, b:10}). Adapt the code above to retrieve samples just from the prior by commenting out thefactorstatement.- Change the prior for to a non-uniform prior, using a Gamma distribution:
var alpha = gamma({shape:0.1, scale:10}). Plot samples from this prior to get a feeling for the shape of this prior. What do you think is going to happen when we use this prior for Bayesian posterior inference?- Add the commented-out
factorstatement back in and inspect the result. Try to see that Bayesian posterior inference over parameters is a mixture of prior and likelihood terms.- What do you think will happen when we increase or decrease the number of observations while keeping the ratio of total observations to observed counts constant (like in a previous exercise)? Try it!
Let us take stock. The last example showed how to do data-driven Bayesian inference of a model parameter. Bayesian parameter estimation tells us what we should rationally believe about the values of parameters, given the observed data and the postulated model. The model in question here contains both the prior and the likelihood function; Bayesian inference depends on the prior over parameters. We can take flat, so-called uninformative priors if we are mainly agnostic in the beginning and simply interested in the shape of the likelihood surface. If parameters are meaningful and if we have knowledge (from previous experiments or other sources), this knowledge can (and some say: should) be fed into the priors and so become part of the modeller’s hypothesis of the data-generating process.
Full example
The previous example only contained a single condition from the experiments reported by reft:QingFranke2013:Variations-on-a. The full data set additionally contains data for (conditions equivalent to) a listener observing the utterance “square” in contexts like Fig. 1, and also the number of times participants chose particular properties. In other words, the data collected contains both (speaker) production and (listener) comprehension data. Following reft:frankgoodman2012, there was also a salience prior condition, which was like a listener condition but where participants were told that the observed word was unintelligible. reft:frankgoodman2012 used data from this condition to feed into the objectPrior of the RSA model (we will enlarge on this below). Here is the full data from reft:QingFranke2013:Variations-on-a and a reminder of what the visual display looked like:
var salience_priors = {
blue_circle: 71, // object "blue circle" was selected 71 times
green_square: 139,
blue_square: 30,
}
var prod_data = {
blue_circle: {blue: 9, circle: 135, green: 0, square: 0},
green_square: {blue: 0, circle: 0, green: 119, square: 25},
blue_square: {blue: 63, circle: 0, green: 0, square: 81}
}
var comp_data = {
blue: {blue_circle: 65, green_square: 0, blue_square: 115},
square: {blue_circle: 0, green_square: 117, blue_square: 62}
}
Several things are noteworthy here. First, in the salience prior condition, most participants found the object with the unique color (green square) the most likely referent, followed by the object with the unique shape (blue circle). The differences between choice counts in the salience prior condition is rather pronounced. We include these counts as an empirically informed proxy for the objectPrior in the RSA model below.
var salience_priors = {
blue_circle: 71, // object "blue circle" was selected 71 times
green_square: 139,
blue_square: 30,
}
// prior over world states
var objectPrior = function() {
categorical({ps: _.values(salience_priors), // empirical data
vs: _.keys(salience_priors)})
}
Infer({model: objectPrior})
Second, as expected from a Gricean or RSA-based point of view, participants more frequently selected a more informative (here: unique) property. But on top of that, there seems to be a tendency to select a shape term. To investigate this issue further we are going to include non-uniform costs into the RSA model. (For more on speaker utilities, see Appendix Chapter 1.) In particular, we include an additive cost term for the use of a color property, like so:
// function for utterance costs
var cost = function(utterance, c) {
(utterance === "blue" || utterance === "green") ? c : 0
}
// pragmatic speaker
var speaker = function(obj, alpha, c){
Infer({model: function(){
var utterance = uniformDraw(utterances)
factor(alpha * (literalListener(utterance).score(obj) -
cost(utterance,c)))
return utterance
}})
}
// pragmatic listener also receives cost term 'c'
The full model, including empirically measured salience priors and cost terms, is this:
// print function 'condProb2Table' for conditional probability tables
///fold:
var condProb2Table = function(condProbFct, row_names, col_names, precision){
var matrix = map(function(row) {
map(function(col) {
_.round(Math.exp(condProbFct(row).score(col)),precision)},
col_names)},
row_names)
var max_length_col = _.max(map(function(c) {c.length}, col_names))
var max_length_row = _.max(map(function(r) {r.length}, row_names))
var header = _.repeat(" ", max_length_row + 2)+ col_names.join(" ") + "\n"
var row = mapIndexed(function(i,r) { _.padEnd(r, max_length_row, " ") + " " +
mapIndexed(function(j,c) {
_.padEnd(matrix[i][j], c.length+2," ")},
col_names).join("") + "\n" },
row_names).join("")
return header + row
}
///
////////////////
// OBSERVED DATA
////////////////
///fold:
var salience_priors = {
blue_circle: 71, // object "blue circle" was selected 71 times
green_square: 139,
blue_square: 30,
}
var prod_data = {
blue_circle: {blue: 9, circle: 135, green: 0, square: 0},
green_square: {blue: 0, circle: 0, green: 119, square: 25},
blue_square: {blue: 63, circle: 0, green: 0, square: 81}
}
var comp_data = {
blue: {blue_circle: 65, green_square: 0, blue_square: 115},
square: {blue_circle: 0, green_square: 117, blue_square: 62}
}
///
////////////
// RSA MODEL
////////////
// set of states (here: objects of reference)
var states = ["blue_circle", "green_square", "blue_square"]
// set of utterances
var utterances = ["blue","circle","green","square"]
// prior over world states
var objectPrior = function() {
categorical({ps: _.values(salience_priors), // empirical data
vs: _.keys(salience_priors)})
}
// meaning function to interpret the utterances
var meaning = function(utterance, obj){
_.includes(obj, utterance)
}
// literal listener
var literalListener = function(utterance){
Infer({model: function(){
var obj = objectPrior();
condition(meaning(utterance, obj))
return obj
}})
}
// function for utterance costs
var cost = function(utterance, c) {
(utterance === "blue" || utterance === "green") ? c : 0
}
// pragmatic speaker
var speaker = function(obj, alpha, c){
Infer({model: function(){
var utterance = uniformDraw(utterances)
factor(alpha * (literalListener(utterance).score(obj) -
cost(utterance,c)))
return utterance
}})
}
// pragmatic listener
var pragmaticListener = function(utterance, alpha, c){
Infer({model: function(){
var obj = objectPrior()
observe(speaker(obj, alpha, c),utterance)
return obj
}})
}
// model parameters
var alpha = 1
var c = 0
// display full probability tables
display("literal listener")
display(condProb2Table(literalListener, utterances, states,2))
// display("speaker")
// display(condProb2Table(function(s) {speaker(s,alpha,c)}, states, utterances,2))
// display("pragmatic listener")
// display(condProb2Table(function(u) {pragmaticListener(u,alpha,c)}, utterances, states,2))
Exercises:
- Look at the changes to
objectPrior, call theliteralListenerfunction for various utterances and make sure that you understand why you see the results that you see.- Look at the speaker’s utterance productions for the “blue_square”. Use cost
c = 0first and then modify the costs to inspect how they change the speaker’s utterance choice probabilities.- Test how different cost values affect the pragmatic listener’s interpretation.
Parameter estimation for full data set
The current model has two parameters, optimality and an utterance cost that differentiates shape from color terms. The latter is theoretically interesting: does the observed data lead us to believe that should be substantially different from zero?
////////////////
// OBSERVED DATA
////////////////
///fold:
var salience_priors = {
blue_circle: 71, // object "blue circle" was selected 71 times
green_square: 139,
blue_square: 30,
}
var prod_data = {
blue_circle: {blue: 9, circle: 135, green: 0, square: 0},
green_square: {blue: 0, circle: 0, green: 119, square: 25},
blue_square: {blue: 63, circle: 0, green: 0, square: 81}
}
var comp_data = {
blue: {blue_circle: 65, green_square: 0, blue_square: 115},
square: {blue_circle: 0, green_square: 117, blue_square: 62}
}
///
////////////
// RSA MODEL
////////////
///fold:
// set of states (here: objects of reference)
var states = ["blue_circle", "green_square", "blue_square"]
// set of utterances
var utterances = ["blue","circle","green","square"]
// prior over world states
var objectPrior = function() {
categorical({ps: _.values(salience_priors), // empirical data
vs: states})
}
// meaning function to interpret the utterances
var meaning = function(utterance, obj){
_.includes(obj, utterance)
}
// literal listener
var literalListener = function(utterance){
Infer({model: function(){
var obj = objectPrior();
condition(meaning(utterance, obj))
return obj
}})
}
// function for utterance costs
var cost = function(utterance, c) {
(utterance === "blue" || utterance === "green") ? c : 0
}
// pragmatic speaker
var speaker = function(obj, alpha, c){
Infer({model: function(){
var utterance = uniformDraw(utterances)
factor(alpha * (literalListener(utterance).score(obj) -
cost(utterance,c)))
return utterance
}})
}
// pragmatic listener
var pragmaticListener = function(utterance, alpha, c){
Infer({model: function(){
var obj = objectPrior()
observe(speaker(obj, alpha, c),utterance)
return obj
}})
}
///
////////////////
// Data Analysis
////////////////
var dataAnalysis = function(){
// priors over parameters of interest
var alpha = uniform({a:0, b:10})
var c = uniform({a:-4, b:4})
// speaker production part
map(function(s){ // anonymous call to "map" around "observe" -> think: for-loop
var speaker_predictions = speaker(s, alpha, c)
var speaker_data = prod_data[s]
var utt_probs = map(function(u){
return Math.exp(speaker_predictions.score(u))
}, _.keys(speaker_data))
var utt_count = map(function(u){
return speaker_data[u]
}, _.keys(speaker_data))
observe(Multinomial({n: sum(utt_count),
ps: utt_probs}),
utt_count)
}, states)
// listener comprehension part
map(function(u){ // anonymous call to "map" around "observe" -> think: for-loop
var listener_predictions = pragmaticListener(u, alpha, c)
var listener_data = comp_data[u]
var int_probs = map(function(s){
return Math.exp(listener_predictions.score(s))
}, _.keys(listener_data))
var int_count = map(function(s){
return listener_data[s]
}, _.keys(listener_data))
observe(Multinomial({n: sum(int_count),
ps: int_probs}),
int_count)
}, _.keys(comp_data))
return {alpha: alpha, costs: c}
}
var parameter_estimation = Infer({
method: "MCMC",
samples: 10000,
burn: 2000,
model: dataAnalysis})
viz(parameter_estimation)
viz.marginals(parameter_estimation)
Exercises:
- Based on the density plot of the marginal distribution of the cost parameter, would you conclude that value
c = 0is credible?
Model criticism
Data-driven parameter inference tells us which values of parameters are credible, given the data and the model. But such an inference is trustworthy and useful only to the extent that the model (think: the theory that feeds into the likelihood function) is credible and justified by the data. It is therefore important to assess how well a given model is able to account for the data. Model criticism is where we ask: which aspects of our data set are (un-)problematic for the model at hand? An answer to this question will often suggest where or how the current model could be revised or whether it should be replaced by an alternative model. It’s here that, ideally, scientific progress and an enhanced understanding happens: “aha, our previous assumptions failed to explain observation such-and-such; to explain this we must rather assume this-and-that”.
A simple but powerful method for Bayesian model criticism are posterior predictive checks. This method looks at the predictions our model makes after it is trained on the data at hand (hence the term “posterior”). We look at the predictions this trained model would make about hypothetical future replications of the same experiment that we used to train the model on (hence the term “predictive”). We then check whether (or better: where) the actually observed data looks different from what we expect to see if the trained model was true. If the trained model systematically fails to generate predicitions that look like the data it was trained on, this is usually a good indication that the model is unable to capture some regularity in the data set. (It then still falls to theoretical considerations to judge how systematic and notionally important any particular divergences are; maybe we care, maybe these aspects are not our research focus.)
Probabilistic programming tools like WebPPL make it easy to gather samples from the posterior predictive distribution:
As the definition above suggests, we merely need to sample parameter values from the posterior distribution, given our data . This, we already know how to do. It is parameter inference and we did it just previously in this chapter. For each sample of from the posterior distribution, we then sample a hypothetical datum from the same likelihood function which we assumed for our original data, i.e., we sample a bunch of , each with probability .
////////////////
// OBSERVED DATA
////////////////
///fold:
var salience_priors = {
blue_circle: 71, // object "blue circle" was selected 71 times
green_square: 139,
blue_square: 30,
}
var prod_data = {
blue_circle: {blue: 9, circle: 135, green: 0, square: 0},
green_square: {blue: 0, circle: 0, green: 119, square: 25},
blue_square: {blue: 63, circle: 0, green: 0, square: 81}
}
var comp_data = {
blue: {blue_circle: 65, green_square: 0, blue_square: 115},
square: {blue_circle: 0, green_square: 117, blue_square: 62}
}
///
////////////
// RSA MODEL
////////////
///fold:
// set of states (here: objects of reference)
var states = ["blue_circle", "green_square", "blue_square"]
// set of utterances
var utterances = ["blue","circle","green","square"]
// prior over world states
var objectPrior = function() {
categorical({ps: _.values(salience_priors), // empirical data
vs: states})
}
// meaning function to interpret the utterances
var meaning = function(utterance, obj){
_.includes(obj, utterance)
}
// literal listener
var literalListener = function(utterance){
Infer({model: function(){
var obj = uniformDraw(states);
condition(meaning(utterance, obj))
return obj
}})
}
// function for utterance costs
var cost = function(utterance, c) {
(utterance === "blue" || utterance === "green") ? c : 0
}
// pragmatic speaker
var speaker = function(obj, alpha, c){
Infer({model: function(){
var utterance = uniformDraw(utterances)
factor(alpha * (literalListener(utterance).score(obj) -
cost(utterance,c)))
return utterance
}})
}
// pragmatic listener
var pragmaticListener = function(utterance, alpha, c){
Infer({model: function(){
var obj = objectPrior()
observe(speaker(obj, alpha, c),utterance)
return obj
}})
}
///
////////////////
// Data Analysis
////////////////
var posterior_predictive = function(){
// priors over parameters of interest
var alpha = uniform({a:0, b:10})
var c = uniform({a:-0.4, b:0.4})
// speaker production part
var PP_speaker = map(function(s){
var speaker_predictions = speaker(s, alpha, c)
var speaker_data = prod_data[s]
var utt_probs = map(function(u){
return Math.exp(speaker_predictions.score(u))
}, _.keys(speaker_data))
var utt_count = map(function(u){
return speaker_data[u]
}, _.keys(speaker_data))
observe(Multinomial({n: sum(utt_count),
ps: utt_probs}),
utt_count)
return multinomial({n: sum(utt_count), ps: utt_probs})
}, states)
// listener comprehension part
var PP_listener = map(function(u){
var listener_predictions = pragmaticListener(u, alpha, c)
var listener_data = comp_data[u]
var int_probs = map(function(s){
return Math.exp(listener_predictions.score(s))
}, _.keys(listener_data))
var int_count = map(function(s){
return listener_data[s]
}, _.keys(listener_data))
observe(Multinomial({n: sum(int_count),
ps: int_probs}),
int_count)
return multinomial({n: sum(int_count), ps: int_probs})
}, _.keys(comp_data))
return {PP_speaker, PP_listener, alpha, c}
}
var postPredSamples = Infer({
method: "MCMC",
samples: 5,
burn: 100,
model: posterior_predictive})
display("Some (badly formatted) samples from the posterior predictive distribution of the speaker data.")
display(mapIndexed(function(i,x) {postPredSamples.support()[i]["PP_speaker"]},
postPredSamples.support()).join("\n"))
The output of this WebPPL program can be collected and processed more conveniently in R with the RWebPPL package. (The code is here.) Plots of the posterior predictive checks for this model are in Fig. 2 (speaker) and Fig. 3 (listener). The red dots indicate the observed data. Clearly, this model is not adequate: it is surprised by the data it was trained on!
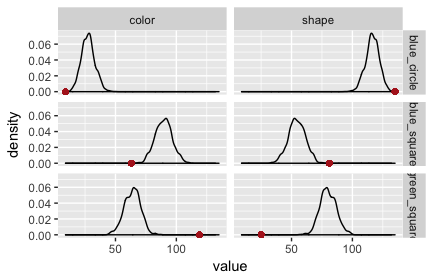
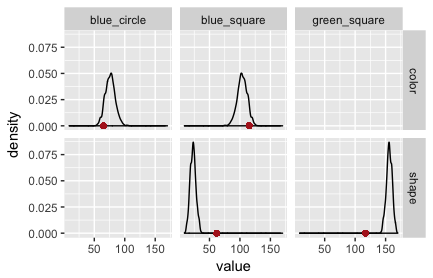
The fault lies in our model code. We assumed that the literal listener uses the empirically measured salience priors. The original RSA model for reference games does not. It assumes that the literal listener (but not the pragmatic listener!) uses a uniform prior over objects/states. If we change the model to this variant, we obtain the PPCs in Fig. 3 and Fig. 4. (The code is here.)
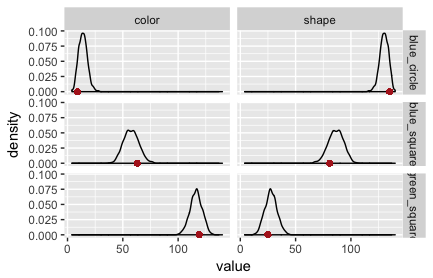
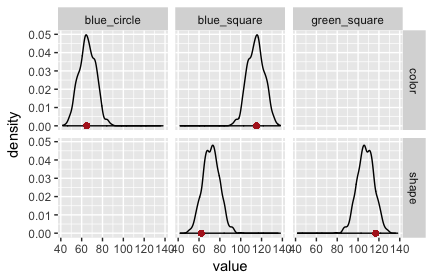
Exercise: Look at the code for the RSA model in the last code box. (You may have to unfold it.) Locate and correct the “mistake”, i.e., implement a version in which the literal listener uses a uniform prior over states, while the pragmatic listener uses the empirically measured salience prior. (You can check your solution by comparing the code for the bad model with that for the good model.)
Model comparison
Model criticism, using visual posterior predicitive checks, clearly suggest that one model is better than the other. Still, this is not yet a quantitative measure of relative model quality. It would be ideal to have a clear and intuitively interpretable criterion for model comparison in terms of the rational beliefs a researcher should adopt about which model is likely, given the observed data. This is exactly how we started this chapter — calculating the posterior probability of a model when there are only two models at hand. In the more general case, we are aware that there are many more conceivable models, some of which might be much better at handling the data, even if we are (currently) unable to specify these models. (We may be aware of the principal possibility of a better theory that would explain some puzzling data, even if we are (currently) unable to conceive of it. Usually, this feeling beseeches us when, even for the best currently known theory , the data is still surprising, as made apparent by model criticism.) In order to avoid quantifying our beliefs about all conceivable models (including a quantification of our beliefs in models that we are unaware of), the standard approach to Bayesian model comparison looks at only two candidate models. In that case, we can easily compute the posterior model odds as a product of the prior model odds and a quantity called the Bayes factor:
Exercise: Show that the equation above follows straightforwardly from a simple application of Bayes rule to the terms .
Posterior model odds are subjective in the sense that they depend on a researcher’s prior beliefs about the models to compare. Bayes factors do not depend on prior beliefs about models (but they still contain a subjective component; see below). Bayes factors quantify how likely the observed data was from each model’s point of view, before the data was observed. This is highly intuitive, and at the heart of many formalizations of observational evidence in philosophy of science: data is evidence in favor of model over if is more likely to happen under than under ; if is rather what would predict than .
The Bayes factor in favor of quantifies how much prior odds should change in light of the data. Bayes factors bigger than 10 are usually considered noteworthy evidence in favor of a model. But even with Bayes factors of 100 in favor of might still belief that is more likely, namely if she started out with a very strong belief in , e.g., from previous belief conditioning on empirical observations.
Computing Bayes factors is difficult for complex models. The reason is that we would need the marginal likelihood of each model, which is exactly the quantity we tried to avoid in parameter estimation (e.g., by using MCMC techniques):
For simple models the marginal likelihood can be approximated reasonably well by naive Monte Carlo sampling. (A model is “simple” in this context, if it has few parameters and/or the priors over parameters put almost all non-negligible probability mass on regions of high likelihood of the data.) Naive Monte Carlo sampling approximates the above integral by taking repeated samples from the prior, computing the likelihood of the data for each sample and then taking the average:
The following code implements naive Monte Carlo (feedforward) sampling to estimate a model’s marginal likelihood for the comparison between two variants of the RSA model: one “uniform” variant in which the literal listener uses uniform priors over states/referents, and one “salience” variant where the literal listener uses the empirically measured salience priors — exactly the models that we looked at previously in the section on model criticism.
////////////////
// OBSERVED DATA
////////////////
///fold:
var salience_priors = {
blue_circle: 71, // object "blue circle" was selected 71 times
green_square: 139,
blue_square: 30,
}
var prod_data = {
blue_circle: {blue: 9, circle: 135, green: 0, square: 0},
green_square: {blue: 0, circle: 0, green: 119, square: 25},
blue_square: {blue: 63, circle: 0, green: 0, square: 81}
}
var comp_data = {
blue: {blue_circle: 65, green_square: 0, blue_square: 115},
square: {blue_circle: 0, green_square: 117, blue_square: 62}
}
///
////////////
// RSA MODEL
////////////
///fold:
// set of states (here: objects of reference)
var states = ["blue_circle", "green_square", "blue_square"]
// set of utterances
var utterances = ["blue","circle","green","square"]
// prior over world states
var objectPrior = function() {
categorical({ps: _.values(salience_priors), // empirical data
vs: states})
}
// meaning function to interpret the utterances
var meaning = function(utterance, obj){
_.includes(obj, utterance)
}
// literal listener
var literalListener = function(utterance, variant){
Infer({model: function(){
var obj = variant == "uniform" ? uniformDraw(states) : objectPrior();
condition(meaning(utterance, obj))
return obj
}})
}
// function for utterance costs
var cost = function(utterance, c) {
(utterance === "blue" || utterance === "green") ? c : 0
}
// pragmatic speaker
var speaker = function(obj, alpha, c, variant){
Infer({model: function(){
var utterance = uniformDraw(utterances)
factor(alpha * (literalListener(utterance, variant).score(obj) -
cost(utterance,c)))
return utterance
}})
}
// pragmatic listener
var pragmaticListener = function(utterance, alpha, c, variant){
Infer({model: function(){
var obj = objectPrior()
observe(speaker(obj, alpha, c, variant),utterance)
return obj
}})
}
///
///////////////////
// Model Comparison
///////////////////
// compute the likelihood of a model variant
// (uniform vs. salience priors in the literal listener)
var LH = function(variant){
// priors over parameters of interest
var alpha = uniform({a:0, b:10})
var c = uniform({a:-0.4, b:0.4})
// likelihood of data for pragmatic listener
var LH_pragmatic = sum(map(function(u){
var listener_predictions = pragmaticListener(u, alpha, c, variant)
var listener_data = comp_data[u]
var int_probs = map(function(s){
return Math.exp(listener_predictions.score(s))
}, _.keys(listener_data))
var int_count = map(function(s){
return listener_data[s]
}, _.keys(listener_data))
return Multinomial({n: sum(int_count), ps: int_probs}).score(int_count)
}, _.keys(comp_data)))
return Math.exp(LH_pragmatic)
}
var n_samples = 5000;
var marginal_likelihood_good = expectation(
Infer({
method: "forward",
samples: n_samples,
model: function() {LH("uniform")}}))
var marginal_likelihood_bad = expectation(
Infer({
method: "forward",
samples: n_samples,
model: function() {LH("salience")}}))
display("Bayes Factor estimate by naive forward sampling:")
marginal_likelihood_good / marginal_likelihood_bad
Exercises:
- What does this numerical result mean? Which model is better? Is this strong or weak evidence in favor of one model?
- Execute this code two or three times and compare the results. The estimate of the Bayes Factor is not stable. Does this imprecision matter?
- Bayes factors depend on the priors over parameters. Change the priors over the cost parameter to allow only positive cost terms (a bias against color terms, in favor of shape terms) but with a wider range, e.g., sample from a uniform distribution with support from 0 to 0.4. Does this change the outcome of model comparison? (Hint: it might be easier to see a difference if you output the Bayes factor in favor of the “bad” model.)
Efficient approximation of marginal likelihoods and Bayes factors is an important area of active research. A short overview of different methods for computing Bayes factors is here.
Table of Contents